
Search the Community
Showing results for '"server capacity"'.
Found 22 results
-

Can servers share their primary resources?
dsturrock replied to freebelion's topic in SI General Discussions
Perhaps I am missing something, but I don't recall Simio ever being able to work as you described. We generally recommend making the server capacity Infinite, so it becomes irrelevant, then relying on a secondary resource to be the constraint. I think this approach will work fine for the case you describe. -
I am working on a model of a production line where one of the work stations is a long work table with six workers at it. These workers perform identical assembly tasks and will sometimes leave the table in order to transport finished items to the next step in production. I am currently representing the work table as a single server. I am wondering if it is possible to dynamically change the server's capacity based on how many workers it is able to seize at a given time. Essentially, the server can process with just one seized worker but can seize up to six. Is this something I can implement with Simio's built in functionality, or is it easier just to represent the six spots in the table as individual servers? Thank you!
-

Change Server Capacity over time with WorkSchedule
JanainaF posted a topic in SI General Discussions
I have a model where I need to set a server had a maximum of 15 entities from 7 A.M to 10 A.M. I Use the WorkSchedule but I don't know how to limit the number of entities. Can someone help me? *This server it is parallel with other servers. -
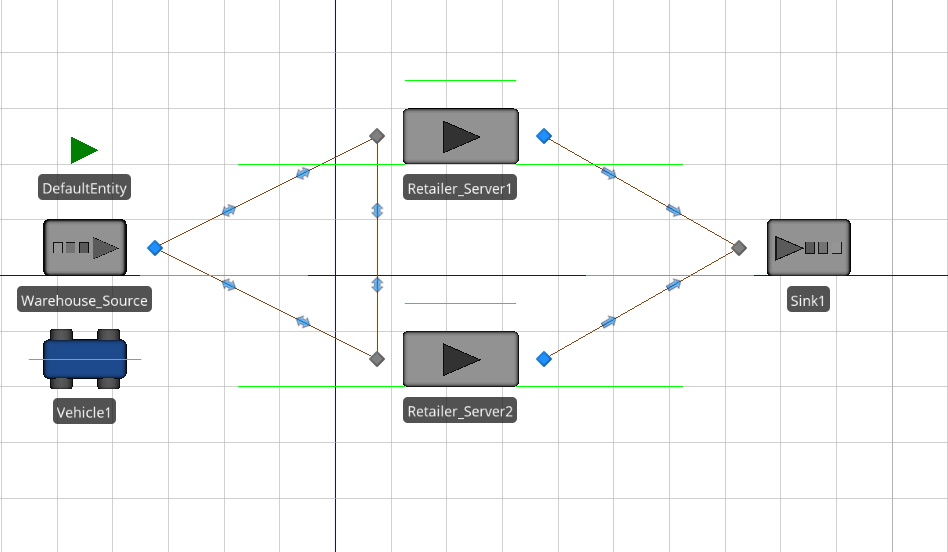
Hi, I made a simple warehouse-retailer model with a source(warehouse), two servers(retailers), and a sink, where the entities(products) are carried from the source to the servers using a single vehicle. The current capacities(demand value at the retailer) of the servers changes after a specific time interval(12-hours and simulation run time of100 days). The Input and Output buffer capacities of both the servers are set to zero. The vehicle leaving the source (Home node) returns back only after serving the respective current capacities of the servers one after the other. As each entity enters the server, its capacity is reduced by 1 unit ultimately reaching zero-current capacity when the full capacity is served. The problem I encounter is that sometimes after my vehicle leaves the source, the current capacity value of the server changes and the new value might be smaller than the previous current capacity value. So my vehicle stays at the input node of the server with the extra entities carried until a new current capacity value is assigned, instead of moving to the next server with whatever entities are left in the vehicle. I don't intend to change the vehicle speed or time interval for capacity changes to rectify this issue. For example, the current capacity values of the servers at time period 1 are Server 1 = 10 & Server 2 = 12. So the vehicle carries 10+12=22 entities from the source to the server 1. Now while the vehicle is moving towards Server 1, if the current capacity changes to Server 1 = 8 & Server 2 = 12, the vehicle stays at server 1 after serving the 8 units and the remaining 14 units stays within the vehicle instead of moving to the next server to serve its capacity. Screenshot of the model is attached. Could anyone help me with this issue? I would really appreciate your support as I have been trying to fix this issue for a while.
-
 My model assigns capacity of 8 to a server. Two types of Entities arrive...A and C. Before each entity is processed, I am assigning the server's process time using two different random distributions, one for A types and another for C types. My question is whether or not the processing times for any 8 entities in the server at a given time will process to different process times? Or, will the process time of the last entering entity reset the process time for the others that are already in the server?
My model assigns capacity of 8 to a server. Two types of Entities arrive...A and C. Before each entity is processed, I am assigning the server's process time using two different random distributions, one for A types and another for C types. My question is whether or not the processing times for any 8 entities in the server at a given time will process to different process times? Or, will the process time of the last entering entity reset the process time for the others that are already in the server? -
Hello, This topic was posted on public discussions and was replied by Dave Sturrock. I am trying to set up a model with server and workers and increase the capacity by adding more resource. I added Data Schedule where I can set the Value to 1 or 2 (workers) but this does not impact the capacity. Please find attached the model. Thanks. Model11.spfx
-
Hello guys, If we add one more resource (worker) to a server, the capacity is basically doubled. I am not able to identify that on a simple model with 1 server and 2 workers. Please any help,
-
 I am working on a simulation of a number of firms processing raw products. If I represent the firms as resources in a server -so that the server capacity represents the number of firms, how could I identify which resource/firm processed a certain batch of products? Can this be done with a server having a capacity of its own, or should I use a pool of (secondary) resources with id labels so I can use that id to label the product batch?
I am working on a simulation of a number of firms processing raw products. If I represent the firms as resources in a server -so that the server capacity represents the number of firms, how could I identify which resource/firm processed a certain batch of products? Can this be done with a server having a capacity of its own, or should I use a pool of (secondary) resources with id labels so I can use that id to label the product batch? -
Hello Simio team. My group and I are currently working on solutions reguarding queue related issues. We are working on a case where we can implement a loop system similar to the Sim Bit called "Add and remove server capacity", altough we would like relate the opening and closing of capacity based on the maximum queue time (5 minutes = Open another server) and (3 minutes = Closer a server) in the TransferRode instead of the numbers entities in the TransferNodes. We have tried to follow the pdf step by step in the Sim Bit, but we have not been able to get it to work. I hope you guys can help us resolve this issue. -Mlars11 Pharmacy.spfx
-

Closing/opening servers or calling in workers to change capacity
CWatson replied to Mkaste's topic in SI General Discussions
We have a SimBit named 'AddAndRemoveServerCapacity' that includes 6 servers and decision logic to turn on/off the server capacity based on the number of entities in the various lines for the 'open' servers. Monitor Elements within the Definitions window are used to evaluate the lines and a common process is used to turn on capacity. Also, for updating the processing time based on the number of workers, see this user forum link for more information - http://www.simio.com/forums/viewtopic.php?f=6&t=2196&p=7147&hilit=change+processing+time+based+on+workers#p7147. -

Capacity change of server with worker as secondary resource
KatieP replied to AR1995's topic in SI General Discussions
If you want to change the capacity of the server at Initialization, create a control property and reference this control value on the Capacity property of each Server. If you want to change the server capacity during the run Assign the variable ServerName.CurrentCapacity the new value. If all workers are always working at the same server, you may want to just batch the orders together then seize the correct number workers (actually, you wouldn't even need to increase the number workers). If one of the above solutions does not help, please attach a model to clarify what you are trying to do. -
Evacuation inputbuffer queue before off-shift
dsturrock replied to farnaz's topic in SI General Discussions
One approach is to put logic in the "Off Shift" add-on process logic that would check to see if the queue has contents, and if so, set the server capacity back to 1. The you would need to wait an hour (probably Execute another process) and reset capacity to 0. If the pivot table already contains what you want, then use the Export button to export to Execl. If not, call the ExcelWrite step from a process at the right time to write out all the information you need. -
Define a state type property named SrvCap. Set server capacity as a referenced property (i.e., SrvCap). Double the value of SrvCap whenever it is required. You can trigger a process for this to happen.
-

More resource, server capacity should double
FOUADELALBI replied to FOUADELALBI's topic in SI General Discussions
Exactly, I meant that I have two workers available for that work. So, the only way to do it is to change the server capacity. Thank you. -
More resource, server capacity should double
dsturrock replied to FOUADELALBI's topic in SI General Discussions
In server 1 you have indicated that you have 2 workers available and you need both of them available for the 2 minute processing time. In server 2 you have indicated that you have 1 worker available and you want it available for the 2 minute processing time. You would expect statistically identical throughput. Perhaps what you meant is that when you have two workers available that work would proceed in half the time. If so, the processing time should be indicated as 1. Or perhaps you don't even need the workers -- if you just change the server capacity via a schedule you will see the throughput automatically change accordingly. -
 Thank you for your reaction. However, I think you've uploaded the wrong model (combustormodel). I think I found the problem though. It seems that when you want to interupt the workers from working when they go off shift, this can only be done when the server capacity is set to 1. Does anybody know why this is and how I can allow multiple workers to work at a station, but still make them stop working when they go off shift? Kind regards, Roeland
Thank you for your reaction. However, I think you've uploaded the wrong model (combustormodel). I think I found the problem though. It seems that when you want to interupt the workers from working when they go off shift, this can only be done when the server capacity is set to 1. Does anybody know why this is and how I can allow multiple workers to work at a station, but still make them stop working when they go off shift? Kind regards, Roeland -
Using Time-Indexed Tables for row referencing
dsturrock replied to neto7912's topic in SI General Discussions
The property that you are attempting to change is Initial Capacity. For ANY property starting with the word Initial, that means the property is looked at exactly once - when the model is initialized. So what ever value you put in there, it will only be used to initialize the server capacity. The best way to do what you want is to use a schedule for the capacity changes, not a time-indexed table. But if you do want to use a Time-indexed table, then you will probably want to take advantage of the On Interval Process option to specify a process when you will Assign the value of Server1.CurrentCapacity each time the active table row is changed. -
Dear members, I could really use your help with the following for my research project: A server that is capable to processing parts in both directions (I can only find tandem servers)? To be specific a waterway lock that is able to transfer ships from one direction to the other. Besides that, there are multiple ship sizes, so server capacity fluctuates over time, depending on entering ships. Any ideas?? Thank you in advance!
-
I constructed a simple model with a single server where I used a rate table for arrivals. The server block capacity was fixed at 2. When I run this model by hand, I see that maximum holding time for the input buffer of the server is just about 24 minutes every time (but the same exact number), just as it would be if the arrival rate was constant throughout a 24-hour period. However, when I run an experiment where I defined the Server1.InputBuffer.Contents.MaximumTimeWaiting as the response variable, the result is 40 minutes for the scenario where the server capacity of 2 is 40 minutes.(I am using version 5.91) I am wondering 1) if I am confusing two different quantities (maybe the maximum holding time result is averaged by dividing by capacity, but that would be a bug, because the capacity should have no effect on the input buffer) or 2) if the randomization seed is the same for every run that I do by hand, which must be the case, because when I reduce the required replication count to 1 for the experiment, I get the same exact result for the single run that I do by hand. If that is the true reason, then I must ask where to change the randomization seed for every run.
-

Moment of schedule and capacity decrease for busy resource
gdrake replied to averbraeck's topic in SI General Discussions
Multi-capacity preemption with the Standard Library Server is a tricky topic. When using capacity schedules, the Server as currently designed works most naturally if the on-shift capacity is a constant. For example, the capacity goes from 1 to 0 and then back to 1, or from 10 to 0 and then back to 10 and so forth. When the Server's capacity goes to 0, it goes into an 'Offshift' state and the processing logic of all entities that have been allocated Server capacity and are located in the Server's 'Processing' station get suspended. That seems fine, though we could also add an option at some point which allows any current entities to finish processing while the Server is in an 'OffShiftProcessing' state (i.e., the Server works overtime to finish any current WIP), but we have not put that sort of behavior option in yet. But that is certainly doable and has been an idea considered before. When the Server goes back into the on-shift 'Processing' state (which means it is processing at least one entity), then all entities in the Server's 'Processing' station resume their processing delay times. The Server comes back on-shift with a capacity less than the number of entities already in-process The current behavior is as mentioned above. The Server just simply resumes all processing. We've discussed before in previous years trying to do something more fancy here, but trying to only partially resume processing would be much more complicated logic. Let's say 10 entities are processing but the capacity is only 1. Which of the WIP entities is the lucky one that is selected to resume processing? Then the 9 entities that are not the chosen one, presumably they would have to be Interrupted and then release the Server capacity that they hold? Because they then have to wait to re-Seize the Server capacity until the single entity finishes processing and releases capacity (thus allowing the next entity to re-seize)? But those 9 entities may be expected to wait in the Server's Processing station? And if so, then you might have to somehow make sure that no new entities who have yet to ever start processing (e.g., entities waiting in the Server's Input Buffer or waiting outside the Server at its 'Input' node if there is no input buffer) can seize the server before the interrupted guys? So you may have to put in some layered allocation rule scheme whereby new entities waiting in the input buffer are a lower priority to seize Server capacity than entities already in the Processing station waiting to re-seize Server capacity)? Or maybe you just Interrupt everybody and stick them in the Input Buffer of the Server and let the specified ranking rule/dynamic selection rule specified on the Server sort them all out? And if it turns out that the next entity who gets the Server capacity was not even WIP on the server when it went off-shift but was a guy who arrived during the off-shift period, then so be it. And so forth. It can be a bit complicated. We've always punted in the past on this topic because of the issues involved, though one of the reasons that we did add the Interrupt step was to give users a chance to customize a Server if they needed to go down this sort of road (as Dave Sturrock mentioned in his last post). The user can then customize the processing behavior of the Server to do what they think works best for them. Another work-around that we have sometimes told users to use multiple Servers each with capacity 1. Not a course for everyone, but for some problems that sort of modeling approach has worked out fine. But that is somewhat of a long-winded explanation of why, although it may be thought of as a 'bug', we've taken a 'works as intended' stance thus far. Though I don't think taking another look at this topic sometime again is a bad idea. I totally understand how a user might naturally expect or want something different. -

Server goes off shift after processing current units
averbraeck replied to sraja2's topic in SI General Discussions
Option 1: The way I often solve it is to create a high-priority 3-hour job that tries to seize the server at the time when it should go down. As it is waiting in the front of the priority-based queue, it will keep the server busy for 3 hours after the previous job has finished. Statistics will not show true idle time, of course... Option 2: Same high-priority job that triggers an add-on process that takes the server off-shift (or decreases capacity by one); after 3 hours, the token increases the server capacity again. Job time for the job that carries out the trigger is e.g., 0.1 second. Assign step: Server.CurrentCapacity := Server.CurrentCapacity - 1. The advantage over a Timer or a schedule change is that you can control what happens with your own 'helper' Entity. Make sure it is a different Entity instance to avoid contaminating the entity statistics of your 'real' entities. Alexander Verbraeck Professor of Systems Engineering and Simulation Delft University of Technology, The Netherlands -
Moment of schedule and capacity decrease for busy resource
gdrake replied to averbraeck's topic in SI General Discussions
Regarding #3, it is correct that by default when a Server goes from off-shift to on-shift that all entities which have already been allocated Server capacity will simply continue processing (even if the scheduled capacity is less than the entities already using the Server. The server's scheduled utilization will be greater than 100 during the time period when it is working over scheduled capacity). Similarly, suppose you have a Server with scheduled capacity of 5 that has 5 entities currently processing on the Server, and the scheduled capacity is decreased from 5 to 4, that capacity decrease does not by default suspend the processing of one of the entities on the server. All 5 entities continue processing and the server's scheduled utilization will be greater than 100 during the time period until at least one of the entities finishes and releases the server. If it is important for you in a model to never have a server being utilized above scheduled capacity while on-shift, then you might add some Interrupt step-related process logic to your model that essentially kicks entities off the server whenever capacity is decreased. The interruption logic will make the entities release the server capacity, store the remaining processing time, and transfer the entities from the processing station back into the input buffer to have to re-seize. You would have control over selection of which entities are desired to get kicked off and of course if having to re-seize the Server then the server's allocation ranking and selection rules would be applicable. The SimBit 'InterruptingServerWithMultipleCapacity.spfx' might be looked at to see an example of interrupting entities on a server, saving the remaining processing time, and then transferring the entities back into the Input Buffer of the Server to have to re-seize capacity in order to continue processing.




