Le défi
par Lee Alan Evans, Ki-Hwan G. Bae et Arnab Roy (Université de Louisville)
Présenté lors de la Conférence d'hiver sur la simulation 2017
Un modèle de simulation à événements discrets est développé pour représenter un système d'évaluation des performances de la distribution forcée, incorporant la structure, la dynamique du système et le comportement humain associé à de tels systèmes. L'objectif de cette étude est d'analyser le comportement humain et d'explorer une méthode de validation du modèle qui capture le rôle de l'ancienneté des subordonnés dans le processus d'évaluation. Cette étude comprend des expériences de simulation qui mettent en correspondance des fonctions de boîte noire représentant le comportement humain avec les résultats de la simulation. L'efficacité de chaque fonction comportementale est basée sur une fonction de réponse multi-objectifs qui est une fonction de somme des erreurs quadratiques mesurant la différence entre les sorties du modèle et les données historiques. Les résultats des expériences démontrent l'utilité de l'application des techniques d'optimisation de la simulation à la phase de validation du modèle de la conception du système de simulation.
Contexte
L'armée américaine a eu recours à diverses techniques pour réduire le nombre de militaires en service actif de plus de 566 000 en 2010 à moins de 470 000 en 2016. Ces techniques comprenaient des conseils de séparation involontaire, des conseils de retraite anticipée, une diminution des adhésions, une diminution des possibilités de réengagement et une diminution des taux de promotion. L'analyse des évaluations des performances est au cœur de chacun de cesmécanismes de formation des forces, à l'exception de la diminution des adhésions.
Les évaluations des performances revêtent une importance significative dans les rangs des officiers en raison de la loi de 1980 sur la gestion du personnel des officiers de défense (Defense Officer Personnel Management Act, DOPMA). Cette loi, adoptée par le Congrès le 12 décembre 1980, fixe le nombre d'officiers en fonction des effectifs globaux de l'armée, mais surtout, elle codifie lesystème de promotion "up-or-out"(Rostker et al. 1993). Cesystèmea été conçu de manière à ce que les officiers soient évalués par des comités de promotion et, s'ils sont sélectionnés, qu'ils gravissent les échelons par cohortes, généralement déterminées en fonction du nombre d'années de service en tant qu'officier. En outre, tout officier dont la candidature n'est pas retenue à deux reprises pour une promotion au grade supérieur est contraint de quitter le service. La seule exception à l'obligation de séparation est une disposition autorisant lacontinuation sélectivepour certains officiers, avec l'intention d'y recourir avec parcimonie. Lesystème de promotion "up-or-out"facilite la structure des grades présentée dans la figure 1, qui a également été définie dans la DOPMA.
L'un des grades les plus touchés par la réduction des effectifs est celui de lieutenant-colonel, qui est passé d'un taux de promotion de plus de 91 % en 2006 à un taux de promotion de seulement 60,2 % en 2016. Une analyse des résultats du comité de promotion montre que les percentiles identifiés dans les évaluations sont le meilleur indicateur pour savoir si un officier a été promu ou non. Le système d'évaluation des performances des officiers de l'armée américaine est un système de distribution forcée qui utilise une comparaison relative des officiers au sein d'un groupe d'évaluation et oblige les évaluateurs à donner les meilleures évaluations à moins de 49 % de leurs subordonnés (Department of the Army Headquarters 2015). Une analyse plus approfondie des résultats du tableau d'avancement montre que l'ancienneté joue un rôle important dans le fait qu'un officier reçoive ou non une évaluation de haut niveau. Toutefois, la fonction utilisée par les évaluateurs pour trier et évaluer les subordonnés est inconnue (boîte noire) et bruyante en raison de la priorité accordée par les évaluateurs à l'ancienneté.

Littérature connexe
Pour les besoins de la conception de ce système de simulation, nous avons passé en revue les méthodes de planification des effectifs, les systèmes d'évaluation des performances, la gestion des talents, l'optimisation de la simulation et la validation des modèles.
Bartholomew, Forbes et McClean (1991) définissent laplanification de la main-d'œuvrecomme "la tentative de faire correspondre l'offre de personnes avec les emplois disponibles pour elles". Wang (2005) classe les techniques de recherche opérationnelle appliquées à la planification de la main-d'œuvre en quatre branches : les modèles d'optimisation, les modèles de chaîne de Markov, les modèles de simulation informatique et la gestion de la chaîne d'approvisionnement par le biais de la dynamique des systèmes. Hall (2009) note que la littérature existante sur la planification de la main-d'œuvre relève de l'un des trois grands thèmes suivants : la programmation dynamique, les modèles markoviens et la programmation par objectifs. Bien que les listes ne soient ni exhaustives ni mutuellement exclusives, nous classons les techniques existantes dans les catégories des modèles d'optimisation, de Markov et de simulation.
Parmi les premiers exemples de modèles d'optimisation, on peut citer les modèles de programmation dynamique qui fournissent un cadre pour la prise de décision en matière de ressources humaines (Dailey 1958, Fisher et Morton 1968). Une application plus récente de la programmation dynamique est celle d'Ozdemir (2013), qui fournit un ordre de traitement analytique de la hiérarchie pour la sélection du personnel. Bres et al. (1980) et Bastian et al. (2015) proposent des modèles de programmation par objectifs pour analyser les effectifs d'officiers et la composition des professions sur un horizon temporel fini. Kinstler et al. (2008) utilise un modèle markovien pour le corps infirmier de la marine américaine afin de déterminer le nombre optimal de nouvelles recrues pour résoudre le problème du sureffectif aux grades inférieurs afin de répondre aux besoins aux grades supérieurs. Bien que les modèles de Markov puissent être utilisés comme des modèles autonomes, ils sont plus couramment incorporés dans des modèles d'optimisation plus vastes (Hall 2009, Zais 2014). Lesinski et al. (2011) et McGinnis, Kays et Slaten (1994) sont des exemples de simulation utilisée pour la modélisation des effectifs. Le concept de simulation développé par Lesinski et al. (2011) est utilisé pour déterminer si le moment et la durée de la formation initiale des officiers soutiennent un nouveau modèle de préparation des unités de l'armée. De même, le modèle de simulation à événements discrets de McGinnis, Kays et Slaten (1994) analyse la faisabilité des politiques de personnel proposées exigeant une durée minimale dans les affectations clés. Ce qui est commun à toutes les méthodes existantes, c'est qu'elles se concentrent sur la satisfaction des besoins sous forme agrégée. En d'autres termes, les modèles estiment les besoins en matière d'adhésions et d'entrées latérales sur la base de l'attrition historique, des promotions et de la croissance prévue. Très peu d'attention est accordée à la modélisation des systèmes qui identifient et sélectionnent les personnes les plus qualifiées pour répondre aux besoins plutôt qu'à la mesure binaire de l'occupation ou de la vacance d'un poste.
Wardynski, Lyle et Colarusso (2010) définissent le talent des officiers de l'armée américaine comme l'intersection des connaissances, des compétences et des comportements individuels. Dabkowski et al. (2010) notent que la mesure des talents des officiers est largement conceptuelle, mais que des mesures réelles ne sont pas nécessaires pour analyser l'impact des politiques sur la rétention des talents. Leur modèle utilise un score de talent normalement distribué pour analyser l'impact de multiples schémas d'attrition sur le talent des cadres supérieurs. Wardynski, Lyle et Colarusso (2010) montrent que les sources de commissionnement dont les critères de sélection sont les plus stricts produisent des officiers plus performants dans les rangs supérieurs, ce qui ajoute de la crédibilité au traitement de Dabkowski et al. (2010) qui considèrent le talent comme une valeur statique et innée.
Les systèmes d'évaluation des performances sont connus pour leurs biais et leurs erreurs inhérents. Les exemples de biais et d'erreurs au sein des systèmes d'évaluation des performances sont difficiles à quantifier, mais comprennent notamment les évaluateurs évaluent plus généreusement (indulgence) ou plus sévèrement (sévérité) que les subordonnés ne le méritent, les évaluateurs forment des opinions positives (halo) ou négatives (corne) autour d'un nombre limité de critères, les performances récentes pèsent lourd (récence), les évaluateurs élèvent la note du subordonné pour se donner une meilleure image (intérêt personnel), et évaluent les subordonnés les uns par rapport aux autres plutôt que par rapport aux normes de performance (contraste/similarité) (Coens et Jenkins 2000, Carroll et Schneier 1982, Kozlowski, Chao, et Morrison 1998). Le physicien et mathématicien W. Edwards Deming ajoute que les résultats des performances individuelles dépendent de la structure d'un système (Elmuti, Kathawala et Wayland 1992). Les résultats de l'évaluation des performances dépendent également de la structure du système. L'imprécision au sein d'un système d'évaluation des performances se réfère à la mesure dans laquelle le résultat de l'évaluation diffère de la véritable distribution des niveaux de performance au sein d'un groupe de salariés évalués (Carroll et Schneier 1982).
La validation d'un modèle de simulation dans le but d'estimer l'imprécision d'un système d'évaluation de la performance est une tâche non triviale. Law (2015) affirme que "le test le plus définitif de la validité d'un modèle de simulation consiste à établir que ses données de sortie ressemblent étroitement aux données de sortie que l'on attendrait du système réel". Il existe de nombreuses méthodes de validation des modèles. Balci (1998) énumère 75 techniques de vérification, de validation et de test de modèles, mais note que la plupart des praticiens utilisent des techniques informelles qui reposent sur le raisonnement humain et la subjectivité.
Énoncé du problème
Kane (2012) note que les évaluations sont souvent liées au poste, plutôt qu'à la performance. Cette situation est plus fréquente dans les branches qui ont des postesclésdedéveloppement. Afin d'atténuer l'effet des affectations des officiers qui influencent la note attribuée, nous utilisons des données strictement pour les majors des domaines fonctionnels avec une homogénéité des affectations. Un domaine fonctionnel est un "regroupement d'officiers par spécialité technique ou compétences autres qu'une arme, un service ou une branche, qui nécessite généralement une éducation, une formation et une expérience uniques", selon le quartier général du département de l'armée (2014).
Les officiers sont évalués à chaque affectation par rapport à leurs pairs ou aux officiers du même grade. La figure 2 présente l'organigramme type d'un officier de l'armée américaine. Les officiers entrent dans le système d'évaluation et sont affectés à ungroupe de leurs pairs, appelé "rating pool". En général, chaque officier fait l'objet d'une évaluation annuelle basée sur ses performances par rapport aux autres officiers du même groupe d'évaluation. Après l'évaluation, l'agent reste dans le même groupe ou est réaffecté à un groupe différent. La réaffectation implique généralement un changement physique de lieu géographique. Lorsqu'un agent a passé un certain temps dans le système, cinq ans dans le cas de la figure 1, il quitte le système. Le dossier de l'officier est présenté à un comité de promotion, composé d'officiers généraux, qui décide si l'officier passe au grade suivant ou s'il est contraint de quitter le service militaire.
Les évaluateurs ne peuvent pas donner une évaluation supérieure à 49 % des officiers de leur groupe. L'objectif de ce mandat de distribution forcée est de fournir une différenciation des performances pour les décisions de gestion du personnel. Les systèmes d'évaluation des performances par répartition forcée appliqués à un petit nombre d'employés entraînent une mauvaise identification des performances. Mohrman, Resnick-West et Lawler (1989) affirment que les systèmes de distribution forcée ne devraient être appliqués qu'à un groupe d'individus suffisamment important, à savoir pas moins de 50 employés. La distribution binomiale permet de quantifier cette mauvaise identification des performances. Si Xestune variable aléatoire représentant le nombre d'agents ayant obtenu les 49 % de notes les plus élevées au sein d'un groupe den agents, et si les performances des agents sont indépendantes, Xsuit la loibinomiale(n, 0,49). Les erreurs d'identification se produisent lorsque le nombre d'agents méritant les meilleures évaluations dépasse la contrainte de profil. Par exemple, sin = 15, E[Erreurs d'identification] est ∑15, x=8 P(X= x)(x -7) = 0,9470.Lorsquen= 100, E[Erreurs d'identification] est ∑100, x=50 P(X= x)(x -49) = 1,9893. Par conséquent, si une population de 300 agents est divisée en 20 groupes d'évaluation, on peut s'attendre à 18,9405 (0,9470 x 20) erreurs d'identification. Les mêmes 300 agents divisés en trois groupes de notation donnent lieu à 5,9680 (1,9893 x 3) erreurs d'identification attendues. D'autres facteurs influent sur la précision des évaluations : la répartition de la taille des groupes de notation, la fréquence des déplacements entre les groupes de notation et le comportement humain au sein du système. Ces facteurs, appliqués sur une période de plusieurs années, nécessitent l'utilisation de techniques telles que la simulation pour quantifier l'erreur induite par un système d'évaluation des performances à distribution forcée.

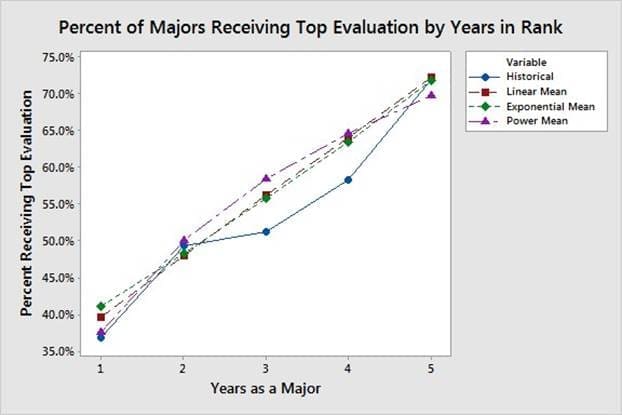
La quantification du comportement des évaluateurs en matière de classement et d'évaluation des subordonnés nécessite l'application de méthodes avancées de validation des modèles. La figure 3 montre que les officiers sont plus susceptibles de recevoir une évaluation de haut niveau à mesure que leur ancienneté dans le grade augmente. La figure 4 montre la distribution du nombre d'évaluations supérieures reçues par les majors sur une période de cinq ans. Les résultats de la simulation correspondant aux distributions présentées dans les figures 3 et 4 sont soumis à la fonction de notation utilisée pour classer et évaluer les subordonnés au sein de chaque groupe de notation, c'est-à-dire une fonction de boîte noire. Les données présentées dans les figures 3 et 4 proviennent de majors ayant participé à des conseils de promotion en 2015 et 2016, avec des taux de promotion de 60,4 % et 60,2 %, respectivement. La base de comparaison du modèle est une moyenne de ces deux années en raison de leur similitude et pour centrer le modèle sur les tendances actuelles de l'évaluation.
La contribution de notre étude est l'examen d'une méthode d'estimation de cette fonction de boîte noire à l'aide de l'optimisation de la simulation. Nous construisons un modèle de simulation à événements discrets et modifions la fonction de tri utilisée pour simuler le comportement humain à l'aide d'OptQuest et de la procédure Kim-Nelson (KN), une méthode d'optimisation de simulation de classement et de sélection entièrement séquentielle. Les paramètres de plusieurs fonctions sont évalués afin de déterminer leur capacité à reproduire le comportement des évaluateurs.
Pour évaluer les résultats, nous utilisons une adaptation de la fonction de coûtJ(θ) d'Ikonen et Najim (2002) présentée sous sa forme générale :

La fonction de coût quadratique de l'équation (1) attribue αkpondérations aux carrés des différences entreKsortiesobservées,y(k), et les prédictions du modèle, θTϕ(k). L'objectif est de minimiser la fonction de coûtJ enfonction des paramètres θ, comme dans l'équation (2) :



La section 4 détaille la dérivation de la fonction de coût et les paramètres du système.
La solution
Description du modèle
Données d'entrée du modèle et dynamique du système
Le modèle de simulation a été développé dans Simio et suit le cadre de la figure 2. Les agents entrent dans le système à un rythme uniforme et se voient attribuer un attributQiqui représente le percentile de performance initial de l'agent, oùQiUniform(0,1). Les agents sont répartis de manière aléatoire dans des groupes de notation. Chaque année, les agents sont triés et reçoivent une évaluation,Xi joù :

Après chaque évaluation, l'agent change de groupe de notation avec une probabilitép oureste dans le même groupe de notation avec une probabilité 1 -p, ce qui simule la dynamique des systèmes dans lesquels les agents changent régulièrement de groupe de notation. La variation de la valeur dep modifie letemps moyen que les agents passent dans chaque groupe. Unp = 0,730 correspond à une moyenne de 16,42 mois dans chaque poste, soit la durée moyenne passée dans le poste par les agents devant les jurys de promotion en 2015 et 2016. Après cinq ans de collecte d'évaluations, les agents quittent le système et l'historique de leurs évaluations de performance binaires est enregistré dans un fichier de sortie. Un fichier de sortie de simulation tronqué est présenté à la figure 5.
Fonctions de tri
Compte tenu des tendances observées dans la figure 3, la propension des évaluateurs à attribuer une évaluation de haut niveau augmente avec l'ancienneté des agents qu'ils évaluent. Par conséquent, la procédure utilisée pour trier les agents fait appel à une combinaison du percentile de performance initiale et d'une fonction du temps passé dans le système. Nous l'annotons comme suit
Qti, où Qti(Qi,t,α),t est letemps (années) passé par l'agent dans le système, et αest un paramètre estimé utilisé pour appliquer un poids au temps passé par l'agent dans le système. Compte tenu du comportement des évaluateurs, nous analysons la qualité de l'ajustement
pour les fonctions croissantes suivantes :
Linéaire :Qti=Qi+ αt(3)
Exponentielle :Qti=Qi+ αt(4)
Puissance :Qti=Qi+ tα(5)
Sortie
La figure 5 montre la sortie de la simulation pour une fonction de tri donnée. L'analyse de chaque fonction de tri consiste en sa capacité à reproduire les données réelles présentées dans les figures 3 et 4. Avant d'optimiser les paramètres de chaque fonction de tri, il est nécessaire de déterminer un domaine raisonnable pour α. Pour l'équation (3),

Un α= 0 signifie que la détermination par le notateur du classement dans le pool de notation est basée uniquement sur le percentile de performance de l'agent lors de son entrée dans le système et que le temps passé dans le système n'entre pas en ligne de compte. De même, un α= 0,4 signifie que le temps passé par l'agent dans le système est au moins 0,4 fois plus important queQilorsquet = 1 et au moins deux fois plus important queQilorsquet = 5 pour déterminer le classement au sein d'un groupe de notation donné. Par conséquent, nous évaluerons 0< α< 0,4 lors de l'optimisation du résultat de l'équation (3).
L'efficacité de l'équation (4) peut également être évaluée en utilisant des limites similaires pour α. Toutefois, dans l'équation (4), 0< α<1 crée une fonction décroissante par rapport au temps passé dans le système. En outre, pour que le temps passé par l'agent dans le système pèse au moins deux fois le poids deQidans la détermination du classement au sein d'un ensemble de notes donné pour l'équation (4) lorsquet = 5, α1,148. Par conséquent, nous limitons le domaine de αpour l'équation (4) à 1< α<1,148. De même, nous limitons αdans l'équation (5) à 0< α< 0,431.
Estimation des paramètres
Fonction de réponse
Afin d'optimiser les résultats de la simulation, nous utilisons une forme de fonction de réponse multi-objectifs introduite par Ikonen et Najim (2002). Le problème est formulé comme suit :
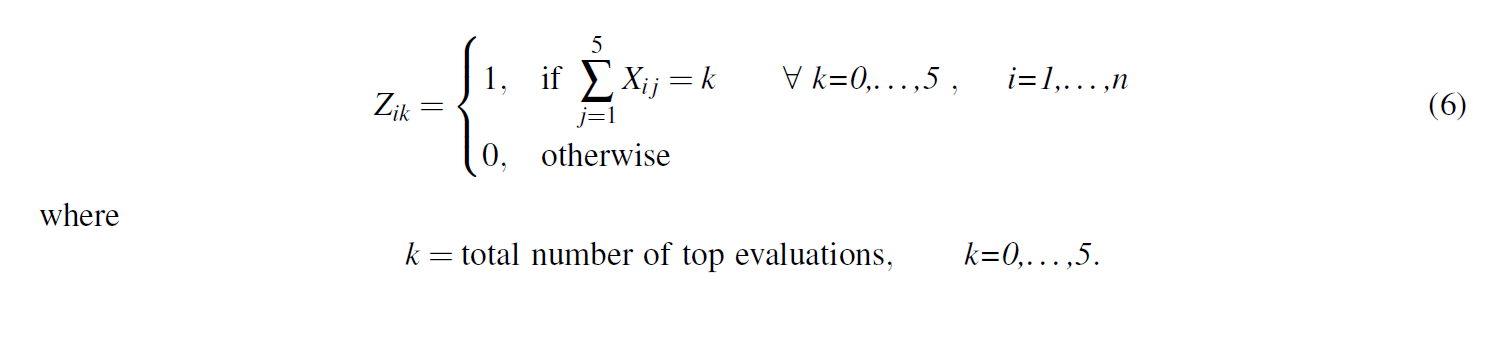
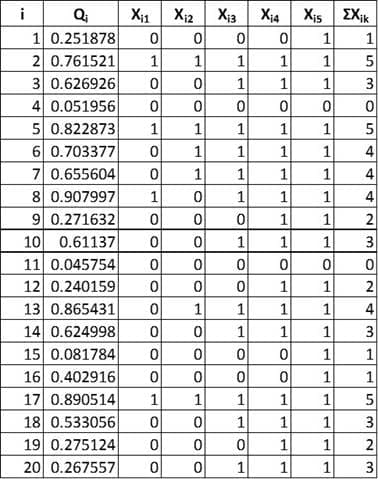
La variable binaireZikdans l'équation (6) est utilisée pour déterminer si chaque agent(i) a reçu 0,1, . . .5 évaluations de haut niveau aucours de la période de 5 ans dans le système. L'équation (7) mesure la différence au carré entre le pourcentage d'agents de la simulation ayant reçukévaluationsmaximalesetAk, où la variableAkest le pourcentage historique d'agents ayant reçukévaluationsmaximales. Cette erreur quadratique est calculée pour chaque valeur dek etadditionnée dans l'équation :

L'équation (7) mesure la qualité de l'ajustement des résultats de la simulation par rapport aux données de la figure 4. Le nombre total des meilleures évaluations reçues par chaque agent est une mesure de la précision du modèle. Une autre mesure de la précision est le moment où chaque agent reçoit les meilleures évaluations. Cette erreur quadratique est calculée pour chaque annéej etadditionnée dans l'équation :
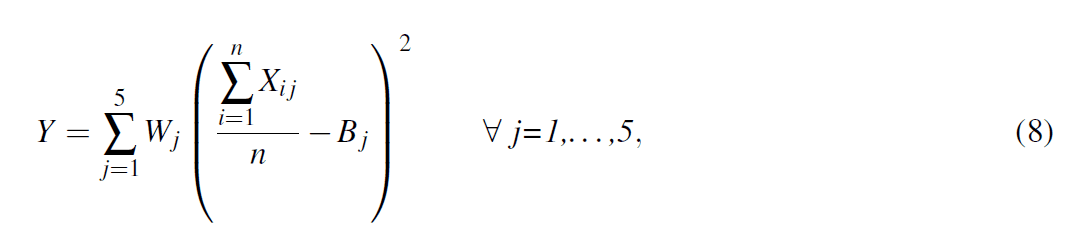
oùB jest le pourcentage d'agents ayant reçu une évaluation supérieure au cours de l'annéej. Les pondérations,Wkdans l'équation (7) etWjdans l'équation (8), nous permettent de contrôler les poids des différences entre chaque résultat de simulation et les données réelles. Cela permet de compenser les différences d'erreur relative ainsi que le nombre inégal de points de données dans l'équation (7) par rapport à l'équation (8). La valeurY de l'équation (8) mesure l'adéquation des résultats de la simulation par rapport aux données de la figure 3. Les mesures d'efficacité fournies dans les équations (7) et (8) peuvent être combinées en une seule mesure de performance pondérée, D = T + Y. Les mesures d'efficacité peuvent être combinées en une seule mesure de performance pondérée.
pondérée,D =T +Y . Le problème consiste alors à trouver la valeur du paramètre αde la fonction de tri qui minimise la fonction objectiveD. Autrement dit, αˆ= arg minD.
α
L'impact sur l'entreprise
Estimation des paramètres à objectif unique
Pour estimer les paramètres de la fonction de tri, nous utilisons la routine d'optimisation par simulation OptQuest (April, Glover et Kelly 2002). L'utilisateur a la possibilité de modifier le nombre minimum et maximum de réplications pour un paramètre d'erreur relative spécifique, ainsi que le nombre maximum de scénarios. Les résultats de la routine OptQuest fournissent la liste des solutions candidates initiales évaluées par la méthode KN, une procédure entièrement séquentielle qui élimine les solutions statistiquement inférieures après chaque réplication. Nous avons exécuté la procédure KN avec une zone d'indifférence de 0,001 sur le meilleur sous-ensemble de scénarios de la routine OptQuest afin de déterminer le réglage optimal du paramètre αdans chaque fonction de tri. Une discussion détaillée de la procédure KN peut être trouvée dans Kim et Nelson (2001). En utilisant le complément Simio OptQuest, l'exécution de 50 scénarios, avec 10 réplications chacun, a pris entre 15 et 16 minutes sur un Intel@ Core i5-4300U à 2,50 GHz avec 8,00 Go de RAM.
Pour l'estimation des paramètres à objectif unique, nous avons réalisé deux expériences distinctes pour trouver les paramètres de chaque fonction de tri résolue :
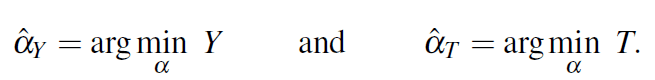
Dans l'équation (8),Bj =[0,368, 0,493, 0,512, 0,582, 0,719], qui représente le pourcentage de majors faisant l'objet d'une promotion en 2015 et 2016 qui ont reçu une évaluation supérieure chaque année dans le classement. Le paramètre αa été évalué dans les équations (3), (4) et (5), et le minimumY pourchaque fonction de tri est indiqué dans la figure 6.
Étant donné queWj =[1,1,1,1,1], le tableau 1 résume les performances de chaque fonction de tri avec les paramètres optimaux. Chaque fonction de tri est comparée à la meilleure dans la colonne "Pourcentage d'écart" du tableau 1.
Tableau 1 : Résumé du minimumY pourchaque fonction de tri avec αdéterminé par l'optimisation de la simulation.
|
Fonction de tri |
Y minimum | Pourcentage d'écart |
|
Linéaire |
0.00674 | 1.81% |
|
Exponentiel |
0.00662 | - |
|
Puissance |
0.00985 | 48.79% |
Le paramètre αa également été évalué dans les équations (3), (4) et (5) et le minimum T pour chaque fonction de tri est indiqué dans la figure 7. Dans l'équation (7),Ak =[0,070, 0,119, 0,231, 0,294, 0,223, 0,064], qui représente les pourcentages historiques d'officiers candidats à une promotion en 2015 et 2016 qui ont reçu [0, 1,...,5] évaluations supérieures totales en tant que major. Étant donné queWk=[1,1,1,1,1,1], le minimum T pour chaque fonction de tri et une comparaison de chaque fonction de tri avec la meilleure sont présentés dans le tableau 2.
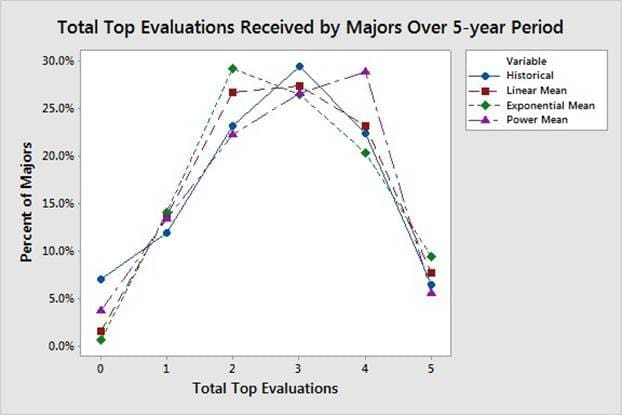
Tableau 2 : Résumé duTminimumpourchaque fonction de tri avec αdéterminé par l'optimisation de la simulation.
|
Fonction de tri |
T minimum | Pourcentage d'écart |
|
Linéaire |
0.0138 | - |
|
Exponentiel |
0.0275 | 99.27% |
|
Puissance |
0.0175 | 26.81% |
Estimation pondérée des paramètres multi-objectifs
Dans l'estimation des paramètres à objectif unique, nous avons utilisé des équations distinctes pour chaque fonction de tri lors de la détermination des valeurs minimales deT et deY . Pour l'estimation des paramètres multi-objectifs, nous avons utilisé une somme pondérée deY etT . Il est donc nécessaire de déterminer lesWj etWk appropriéspour lafonction de réponse,D. L'équation (8) résume l'erreur quadratique entre six sorties de simulation et les données historiques, tandis que l'équation (7) résume l'erreur quadratique entre cinq points de données et les données historiques. Par conséquent, nous commençons par fixer chaque composante deWkà5/6 afin de pondérer les sorties deT etY de manière égale. Enfin, nous tenons compte de l'erreur relative dans Wk. La valeur moyenne des réponses utilisées dans l'équation (7) est de 0,535, ce qui représente le pourcentage moyen de majeures recevant une évaluation de haut niveau au cours d'une année donnée. La valeur moyenne des réponses utilisées dans l'équation (8) est de 0,167, ce qui représente le pourcentage moyen de majors recevant chacune des six possibilités pour un nombre total d'évaluations de haut niveau. Nous compensons la différence de magnitude en multipliant leWk initialpar3,21 (0,535/0,167) et chaque composante du vecteurWkest de2,675 (3,21 5/6). Par conséquent, lors de l'évaluation deD, nous utilisonsWj =[1,1,1,1,1] etWk=[2,675,2,675,2,675,2,675,2,675,2,675,2,675]. La figure 8 montre que la minimisation deD neminimise pasY ouT .
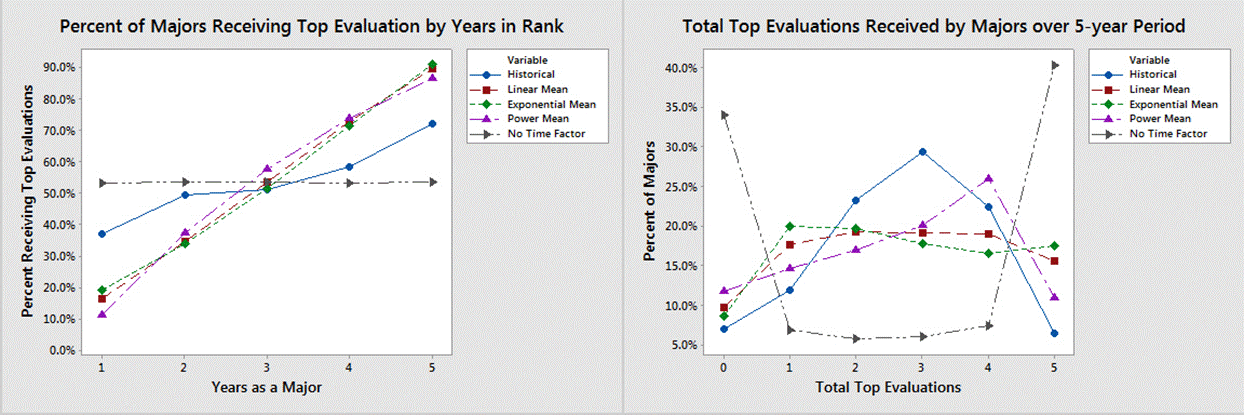
L'efficacité de notre approche multi-objectifs pondérée est illustrée par les deux graphiques de la figure 9. La ligne intitulée "Pas de facteur temps" représente un niveau de performance statique sans facteur temps ajouté, ce qui donneD = 0,864. Le compromis entreT etY illustréà la figure 8 se traduit par une diminution du pourcentage d'amélioration par rapport aux réponses à l'estimation des paramètres à objectif unique résumées dans les tableaux 1 et 2. Le tableau 3 montre la valeur de D en utilisant les paramètres optimaux pour chacune des trois fonctions de tri.
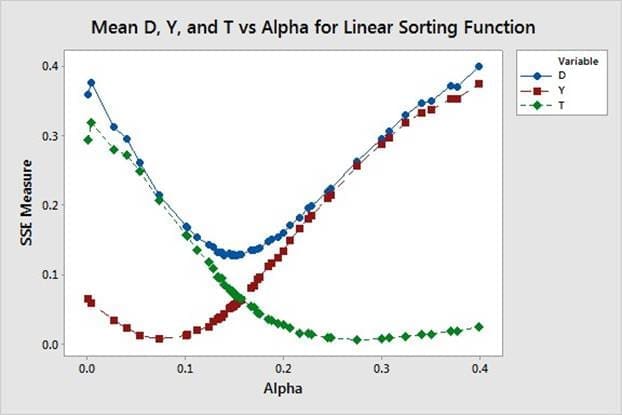
Tableau 3 : Résumé de la valeur minimale deD pourchaque fonction de tri avec αdéterminé par l'optimisation de la simulation.

Conclusions
Les fonctions de tri évaluées dans les expériences décrites précédemment représentent une augmentation du niveau de performance perçu en fonction du temps. Il peut s'agir d'une amélioration réelle des performances, de la tendance de l'évaluateur à récompenser l'ancienneté ou d'une combinaison des deux. Les fonctions évaluées ne constituent pas une liste exhaustive de possibilités, mais représentent plutôt un ensemble facilement interprétable avec des limites supérieures et inférieures claires pour le paramètre α, qui démontrent l'effet de l'ancienneté dans le processus d'évaluation. L'objectif de la sortie du modèle dicte la fonction de tri la plus appropriée : une fonction de tri exponentielle pour minimiserY , une fonction de tri linéaire pour minimiserT , ou une fonction de tri puissance pour minimiserD. Les recherches futures exploreront l'utilisation de polynômes d'ordre supérieur pour mieux représenter le comportement humain dans le modèle. La quantification de l'effet de l'ancienneté dans le processus d'évaluation aidera les professionnels des ressources humaines à déterminer dans quelle mesure les évaluations des performances représentent les niveaux de performance réels des agents par rapport à leurs pairs.
REMERCIEMENTS
Cette recherche a été partiellement financée par la Fondation Omar Nelson Bradley. Les opinions exprimées dans cet article sont celles des auteurs et ne reflètent pas nécessairement la politique ou la position officielle du Commandement des ressources humaines de l'armée américaine, du Département de l'armée, du Département de la défense ou du gouvernement des États-Unis.