Le défi
par Theodore T. Allen et Enhao Liu (Université de l'État de l'Ohio)
Présenté lors de la Conférence d'hiver sur la simulation 2018
Cet article propose un modèle de simulation à événements discrets d'une organisation qui assure la maintenance d'hôtes informatiques et encourt plusieurs millions de dollars en coûts de maintenance et de réponse aux incidents. La politique de maintenance courante est désignée sous le nom de "out-of-sight is out-of-mind" (OSOM), car la majorité des hôtes sont absents des scans et ignorés. Les hôtes sont "sombres" (absents) parce qu'ils ne sont pas accessibles (éteints ou avec des autorisations restreintes). Le modèle proposé est utilisé pour comparer OSOM avec d'autres solutions, notamment des analyses améliorées qui rendent visibles les vulnérabilités des hôtes obscurs. Les résultats clarifient les avantages apparents d'OSOM, à moins que les coûts indirects liés aux intrusions ou à l'amélioration des politiques ne soient pris en compte. En outre, les avantages de l'utilisation des systèmes d'exploitation Windows et des politiques améliorées sont clarifiés, y compris les millions d'économies attendues (par rapport à Linux).
Introduction
Les coûts liés à la cybersécurité sont importants à de multiples niveaux, de la politique nationale et internationale aux réseaux électriques reliant des milliers d'organisations, en passant par les dépenses au sein de chaque organisation. Des modèles d'événements discrets ont exploré les effets politiques (Naugle et al. 2016). Les modèles au niveau du réseau électrique comprennent ceux décrits par Nguyen et al. (2015). De même, les modèles de simulation d'attaque comprennent ceux de Shinet et al. (2015) et de Case (2016).
Dans le cadre de nos propres recherches, nous avons exploré des modèles de processus de décision de Markov pour les dépenses organisationnelles en nous concentrant sur l'évolution d'hôtes uniques (Afful-Dadzie et Allen 2014 ; 2016). Les hôtes informatiques peuvent être des ordinateurs personnels ordinaires, des ordinateurs portables, des serveurs, des imprimantes ou même du matériel d'exercice. Ici, nous nous concentrons uniquement sur les appareils connectés à l'internet qui pourraient être compromis et qui sont scannés et entretenus. Ces appareils sont utilisés pour les étudiants, la recherche et les tâches administratives. Ces appareils présentent ce que l'on appelle des "vulnérabilités", c'est-à-dire des faiblesses que les attaquants peuvent exploiter. Par exemple, un hôte peut utiliser un mot de passe faible, un logiciel dont le cryptage est obsolète ou un logiciel qui ne vérifie pas suffisamment la taille des entrées et des sorties. Ces vulnérabilités sont évaluées par le National Institute of Standards (NIST) des États-Unis et par le système commun de notation des vulnérabilités.
Nous proposons ici d'étendre les données et les hypothèses relatives à l'élaboration d'une politique de maintenance à des simulations d'événements discrets. Cela est similaire à la gestion des correctifs dans les services publics d'électricité abordée par Gauci et al. (2017), sauf que nous considérons un plus grand nombre d'incidents passés et un assortiment plus large de politiques et de types d'hôtes. Les avantages de la simulation d'événements discrets comprennent des moyens relativement intuitifs d'inclure la création et la destruction des hôtes et des ressources limitées de correctifs et de réponse aux incidents. Nous soutenons qu'il est important de prendre en compte les problèmes de "fin de vie" des hôtes car, de manière anecdotique, nous avons connaissance d'hôtes que l'on croyait hors d'usage et qui ont été utilisés et ont causé des incidents.
D'après notre expérience, une politique courante consiste à exiger que le personnel tente de corriger ou d'atténuer les vulnérabilités de niveau élevé ou critique dans un délai d'un mois à partir du moment où la vulnérabilité est observée dans les analyses mensuelles. Cette politique ne tient pas compte des vulnérabilités de niveau moyen ou faible qui ont tendance à s'accumuler. En outre, 70 % des quelque 50 000 hôtes distincts que nous avons étudiés n'ont pas été détectés au cours d'un mois donné. Cela peut être dû au fait que l'hôte est éteint pendant l'analyse ou que les autorisations ne sont pas suffisantes. Certaines méthodes pour imputer les vulnérabilités manquantes dans les données d'analyse sont décrites par Afful-Dadzie et Allen (2014 ; 2016). Récemment, nous avons mis au point des méthodes permettant de prédire avec une grande précision (0,05 % d'erreurs) les vulnérabilités des hôtes qui ne sont pas présentes ("sombres") dans les analyses mensuelles.
Nous examinons ici les implications de 21 mois de transitions observées d'un mois à l'autre sur environ 50 000 hôtes. Les estimations des probabilités de transition qui en résultent sont présentées dans le tableau 1. Les probabilités reflètent les effets combinés d'au moins quatre facteurs. Premièrement, les utilisateurs des hôtes ajoutent constamment des logiciels et ceux qu'ils ont déjà ajoutés vieillissent. Deuxièmement, les pirates informatiques sont constamment à la recherche de vulnérabilités, observent la reconnaissance des vulnérabilités signalées publiquement et obtiennent des exploits (qui sont également souvent publiés gratuitement). Troisièmement, les fournisseurs tentent constamment de corriger automatiquement leurs logiciels à distance. Quatrièmement, le personnel tente de corriger les vulnérabilités conformément à la politique de l'organisation à l'aide de listes de vulnérabilités obtenues à partir de scans et des résultats de leurs propres recherches de correctifs disponibles, en testant les correctifs obtenus pour s'assurer qu'ils ne détruisent pas la fonctionnalité et en appliquant les correctifs trouvés et testés (s'il y en a).
Ici aussi, nous ne considérons que deux types d'hôtes. Il s'agit des hôtes Linux et Windows pour lesquels l'utilisateur dispose des privilèges d'administrateur pour installer de nouveaux logiciels et pour lesquels l'hôte n'est pas contrôlé par les administrateurs. (Les hôtes contrôlés sont généralement beaucoup plus sûrs.) Nous nous référons ici à la politique de maintenance commune dans laquelle les hôtes sombres sont ignorés comme "out-of-site is out-of-mind" (OSOM). L'un des principaux objectifs de cet article est de clarifier les problèmes liés à la politique OSOM et les avantages possibles de politiques plus sophistiquées.
Tableau 1 : Estimation des données de transition d'une grande université (a) hôtes Linux, (b) transitions modifiées reflétant l'amélioration de l'informatique, (c) hôtes Windows, et (d) changements résultant de l'amélioration de l'informatique.
(a)
| Faible-Med. | Faible-Med. | Haut-Crit. | Haut-Crit.-Foncé | Comp. | Comp.-Foncé | |
|---|---|---|---|---|---|---|
| Faible-Med. | 0.2820 | 0.6580 | 0.0177 | 0.0413 | 0.0005 | 0.0005 |
| Faible - Moyen - Foncé | 0.2820 | 0.6580 | 0.0177 | 0.0413 | 0.0005 | 0.0005 |
| Critère élevé | 0.1290 | 0.3010 | 0.1560 | 0.3640 | 0.0250 | 0.0250 |
| Très critique - foncé | 0.0000 | 0.0000 | 0.2250 | 0.7000 | 0.0250 | 0.0500 |
| Comp. | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| Comp.-Foncé | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.8000 | 0.2000 |
| (b) | ||||||
| Très critique - sombre | 0.1290 | 0.3010 | 0.1560 | 0.3640 | 0.0250 | 0.0250 |
(c)
| Faible-Med. | Faible-Med.-Foncé | Haut-Crit. | Haut-Crit.-Foncé | Comp. | Comp.-Foncé | |
|---|---|---|---|---|---|---|
| Faible-Med. | 0.2760 | 0.6440 | 0.0239 | 0.0559 | 0.0001 | 0.0001 |
| Faible - Moyen - Foncé | 0.2760 | 0.6440 | 0.0239 | 0.0559 | 0.0001 | 0.0001 |
| Critère élevé | 0.1444 | 0.3369 | 0.1554 | 0.3627 | 0.0003 | 0.0003 |
| Très critique - foncé | 0.0000 | 0.0000 | 0.2988 | 0.7000 | 0.0006 | 0.0006 |
| Comp. | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| Comp.-Foncé | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.8000 | 0.2000 |
| (d) | ||||||
| Très critique - sombre | 0.1444 | 0.3369 | 0.1554 | 0.3627 | 0.0003 | 0.0003 |
Le mode proposé
Taille de l'unité et période de temps
Notre modèle de simulation à événements discrets spécifie nécessairement le nombre de serveurs et d'entités typiques du système (Allen 2011 ; Law et Kelton 2000). Nous avons observé qu'une grande université est généralement organisée en plusieurs départements, largement indépendants, chacun disposant d'une centaine d'hôtes. Chaque organisation dispose d'un administrateur principalement chargé de réparer les vulnérabilités et de faciliter les réponses aux incidents connus. Par conséquent, le modèle inclut un peu plus de 100 hôtes (en moyenne) sur une période de plus de 100 ans afin de refléter approximativement les coûts de maintenance et de réponse d'une université. Comme indiqué dans AffulDadzie et Allen (2016), nous supposons que les coûts de correction des vulnérabilités s'élèvent en moyenne à 150 dollars et que la réponse aux incidents connus coûte en moyenne 2 000 dollars. Par conséquent, les impacts des vulnérabilités sont pris en compte, mais uniquement en relation avec les coûts directs liés à l'intervention légale en cas d'incidents connus.
États membres
Comme Afful-Dadzie et Allen (2016), nous classons les hôtes en fonction de la vulnérabilité présentant le risque le plus élevé, c'est-à-dire qu'un hôte présentant une vulnérabilité critique est considéré comme critique. Dans la politique commune, les hôtes à risque faible ou moyen sont généralement ignorés. Les hôtes peuvent également être compromis, par exemple lorsque l'hôte est équipé d'un logiciel malveillant qui tente de contacter le pirate ou l'équipe de pirates, mais qui est intercepté par le système de prévention des intrusions. Étant donné que certains hôtes sont "sombres" dans l'analyse et que certaines intrusions sont inconnues, nous prenons en compte les états en plus de l'état de l'hôte mis à la poubelle ou recyclé. Les états comprennent des combinaisons visibles et obscures de faible-moyen, haut-critique et compromis. Les combinaisons faible et moyen et élevé et critique sont associées parce qu'elles sont souvent considérées comme équivalentes dans les politiques organisationnelles.
Il convient de noter que la connaissance des vulnérabilités ou des intrusions peut ne pas contribuer à la réalisation des objectifs de l'organisation. Pourtant, l'observabilité est clairement une propriété souhaitable des systèmes "résilients" (Allen et al. 2016). L'un des principaux objectifs de cet article est de clarifier les avantages possibles d'une meilleure observabilité.
La solution
Modèle SIMIO
Le modèle est implémenté dans le logiciel SIMIO. Le "NewHosts" en haut à gauche de la figure 1 ci-dessous est la source avec des hôtes allant vers le nœud de vulnérabilité faible-moyenne où il n'y a pas de traitement. Cette absence de traitement (recherche, test et application de correctifs s'ils existent) est une mesure d'économie courante qui consiste à ignorer les vulnérabilités cybernétiques faiblement évaluées. Jusqu'à récemment, en raison des difficultés d'inspection, toutes les vulnérabilités cybernétiques non liées à un réseau étaient largement ignorées, y compris par de nombreuses universités et autres organisations. C'est pourquoi elles sont également ignorées ici. Tous les chemins sont des "chemins temporels" fixes qui correspondent à un mois.
Les poids sont proportionnels aux probabilités du tableau 1. Les nœuds sans traitement correspondent aux états 1, 2 et 4. Les serveurs correspondent aux états 3, 5 et 6. Même si l'état sombre compromis ne nécessite pas de travail de la part du personnel interne, un serveur est utilisé pour enregistrer les informations relatives aux coûts de cet état. Le nœud de mise hors service se trouve à droite sur la figure 1 et les hôtes y sont recyclés ou envoyés dans des décharges. Dans l'ensemble, les hôtes sont créés à gauche et vont vers la destruction à droite. Ils passent d'un état de sécurité en haut à la vulnérabilité et à la compromission en bas.
Bien entendu, dans le monde réel, les ordinateurs résident dans des bureaux ou des cafés et ne subissent que peu de mouvements (à l'exception des ordinateurs portables et des téléphones cellulaires). Par conséquent, la logique habituelle de déplacement des hôtes est appliquée comme indiqué dans la figure 2. Les hôtes se déplacent au début et à la fin de leur "vie", lorsqu'ils sont mis en décharge.
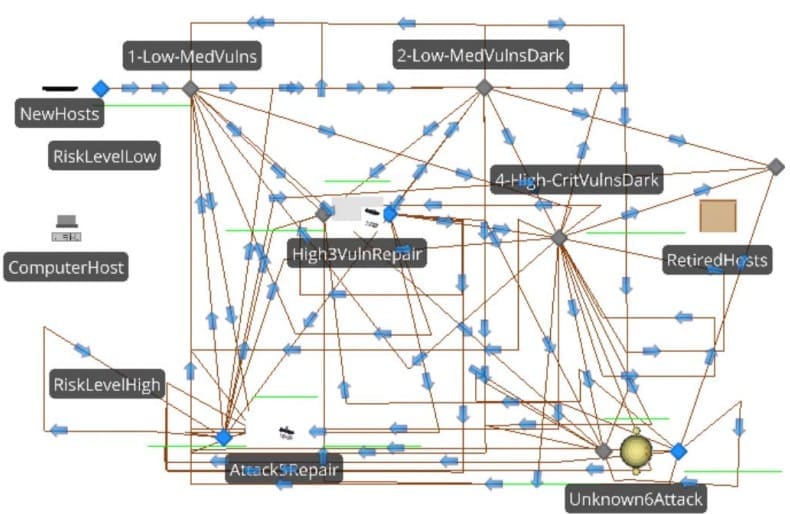
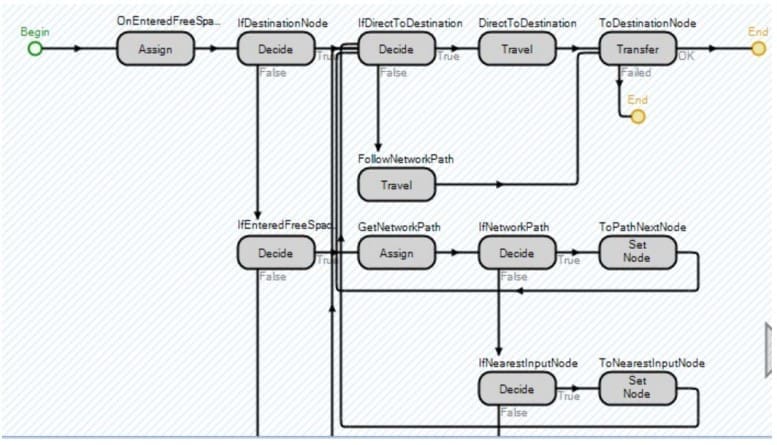
Les principales différences entre le modèle de la figure 1 et le modèle de processus décisionnel de Markov d'Afful-Dadzie et Allen (2016) sont l'inclusion de la naissance et de la mort des hôtes et l'exploration relativement moins approfondie des politiques optimales. L'un des principaux atouts des processus décisionnels de Markov est leur capacité à générer des politiques de contrôle optimales. Cependant, la qualité de ces politiques "optimales" est limitée par les hypothèses associées. En outre, les attaques inconnues sont prises en compte ici dans le modèle de simulation, ce qui n'était pas le cas auparavant.
L'impact sur l'entreprise
Résultats bruts
Les résultats bruts de SIMIO sont présentés dans le tableau 2. Dans les résultats, 100 réplications sont utilisées pour maintenir les demi-largeurs des intervalles de confiance à 95 % à moins de 1 % des quantités estimées. Les résultats incluent "H3VRStation1" pour préciser qu'ils ne tiennent compte que des visites à la station de réparation visible et non des vulnérabilités obscures ou inconnues. Ces coûts hypothétiques sont ajoutés dans les dérivations de l'analyse des résultats afin qu'ils ne soient pas directement dérivés des simulations. Les scénarios Linux sont dérivés des probabilités du tableau 1(a) et (b) et les scénarios Windows sont dérivés des probabilités du tableau 1(c) et (d).
Les résultats du tableau 2 concernent le nombre d'hôtes visitant chaque nœud. La visite d'un nœud de réparation ou d'incident entraîne directement un coût, car un membre du personnel doit tenter de corriger les vulnérabilités concernées ou de répondre aux incidents pertinents. Par conséquent, les coûts du scénario sont de 150 $ × (Nbre moyen de réparations) + 2 000 $ × (Nbre moyen d'incidents).
Tableau 2 : Résultats bruts de SIMIO à partir de 100 réplications pour le nombre d'arrivées aux trois stations clés et les coûts moyens ou prévus associés. Les quatre "objets" ou serveurs clés sont "Active5Repair" (A5R), "High3VulnRepair" (H3VR) et "Unknown6Attack" (U6A).
| Scénario | Nom de l'objet | Moyenne # | Demi-largeur | Stdev. | Exp. Coût | Stdev. | Scén. Totaux |
|---|---|---|---|---|---|---|---|
| Linux | A5R | 1241.5 | 8.2 | 40.8 | $2,482,980 | 81,557 | - |
| Linux | H3VR | 6915.9 | 30.7 | 152.8 | $1,037,387 | 22,927 | - |
| Linux | U6A | 1529.4 | 11.1 | 55.4 | $3,058,860 | 110,719 | $6,579,227 |
| Linux No D. | A5R | 1051.4 | 6.7 | 33.4 | $2,102,700 | 66,825 | - |
| Linux No D. | H3VRStation1 | 5733.1 | 25.7 | 127.6 | $2,866,565 | 63,808 | - |
| Linux No D. | U6A | 1201.5 | 8.4 | 41.7 | $2,402,920 | 83,436 | $7,372,185 |
| Fenêtres | A5R | 114.8 | 2.3 | 11.3 | $229,660 | 22,511 | - |
| Fenêtres | H3VR | 8528.2 | 33.8 | 168.0 | $1,279,229 | 25,198 | - |
| Fenêtres | U6A | 69.0 | 2.1 | 10.6 | $137,980 | 21,133 | $1,646,869 |
| Windows No D. | A5R | 90.5 | 2.0 | 10.0 | $180,920 | 20,049 | - |
| Windows No D. | H3VRStation1 | 5902.8 | 25.4 | 126.3 | $2,951,415 | 63,139 | - |
| Windows No D. | U6A | 46.5 | 1.5 | 7.6 | $93,080 | 15,102 | $3,225,415 |
| Linux No Darkness | H3VRStation1 | 5733.1 | 25.7 | 127.6 | $2,866,565 | 63,808 | $7,372,185 |
| Hypothèse Windows | H3VRStation1 | 5902.8 | 25.4 | 126.3 | $2,951,415 | 63,139 | $864,283 |
Comparaison des alternatives
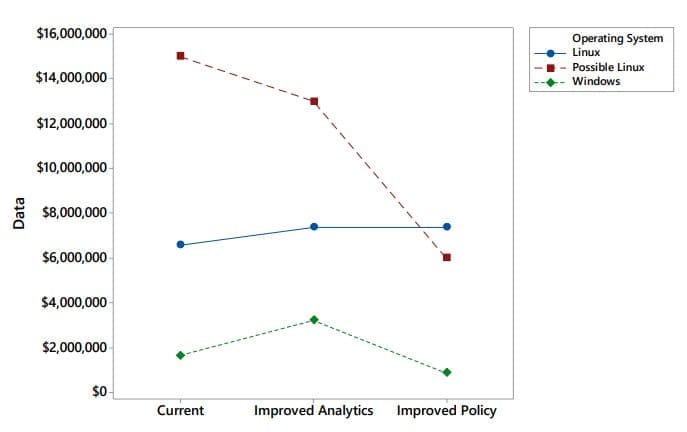
Six systèmes sont comparés dans la figure 3 par rapport aux coûts prévus. Les résultats pour les systèmes actuels Linux et Windows découlent directement de la simulation avec les entrées du tableau 1 et les résultats du tableau 2. La politique dite "d'analyse améliorée" pour chaque système concerne simplement les probabilités ou les poids provenant du tableau 1(b) ou du tableau 1(d) pour les systèmes d'exploitation Linux et Windows respectivement. Ces changements correspondent au fait de rendre l'état 4 équivalent à l'état 3 en termes de performances, de sorte que des opérations de correction supplémentaires se produisent. En d'autres termes, les vulnérabilités cachées sont révélées. Cela a ajouté 1/0,3 fois le coût du serveur dans l'état 3 (A3VR).
Les estimations relatives au système "Linux possible" sont basées sur l'intervention d'un expert. Des questions sur ce qui serait attendu et ce qui serait plausiblement trop élevé ou trop faible ont été utilisées pour obtenir des estimations qui incluent raisonnablement les coûts des incidents inconnus grâce à un processus d'élicitation de type marketing (Allen et Maybin 2004). Les résultats possibles pour Linux sont censés refléter les avantages liés à la connaissance des vulnérabilités des hôtes obscurs.
Les estimations de la politique améliorée sont basées sur les résultats probables qui pourraient se produire si seules les vulnérabilités critiques (1/5 vulnérabilités ou moins) étaient corrigées sur les systèmes Windows. En raison de l'application vigoureuse de correctifs automatiques, nos analyses des processus décisionnels de Markov indiquent qu'il n'est pas rentable de corriger les vulnérabilités élevées sur certains types de systèmes Windows (Afful-Dadzie et Allen, 2016). Pourtant, il y aurait presque certainement des avantages à corriger les vulnérabilités critiques sur les hôtes sombres. C'est pourquoi certains des résultats de la figure 3 se rapportent à des résultats de simulation, tandis que d'autres sont des estimations issues d'avis d'experts recueillis.
Conclusions et travaux futurs
Cet article propose un modèle de simulation à événements discrets pour prévoir les coûts des correctifs et des incidents. Les modèles sont basés sur des centaines de milliers de transitions enregistrées. Cependant, il y a aussi des extrapolations considérables, y compris le coût effectif des politiques améliorées ou des pertes dues à des incidents inconnus. Compte tenu de ces limites, les conclusions suivantes se dégagent :
- Les hôtes Windows nécessitent des coûts de maintenance nettement inférieurs à ceux des hôtes Linux dans notre ensemble de données et nos prévisions de simulation. Cela suppose que les propriétaires des hôtes disposaient de privilèges d'administrateur, ce qui rend l'exploitation de ces hôtes relativement risquée. Cependant, les correctifs automatiques vigoureux apportés par Microsoft sont probablement associés à des coûts de maintenance organisationnels moins élevés.
- Rendre les hôtes Windows sombres visibles grâce à des analyses améliorées ne semble pas être justifié en termes de coûts. En effet, le coût du traitement des 70 % de vulnérabilités ignorées par la politique "hors site, hors esprit" ne serait pas compensé par la réduction des incidents connus. Cependant, si les pertes pour la société dans son ensemble pouvaient être estimées avec précision, la réduction des incidents résultant de l'application de correctifs aux vulnérabilités obscures pourrait être compensée.
- Rendre les hôtes Linux obscurs visibles grâce à une meilleure analyse est à peu près justifié en termes de coûts et serait probablement bénéfique pour le système en améliorant la résilience et en apportant des avantages à la société.
- Rendre visibles les hôtes sombres de tous types est probablement justifié en termes de coûts si les analyses améliorées sont combinées à une politique améliorée. Par exemple, pour les hôtes Windows, une grande partie ou la totalité des vulnérabilités élevées pourraient être ignorées car les correctifs automatiques en traitent probablement beaucoup, mais les vulnérabilités critiques des hôtes sombres pourraient être prédites et corrigées afin de réduire les coûts liés aux incidents.
Les principales limites du modèle proposé concernent les caractéristiques qui ne sont pas prises en charge. Des métamodèles multifidélité pourraient permettre d'améliorer la capacité de prescription (par exemple, en utilisant les méthodes de planification et d'analyse d'Allen et Bernstheyn 2005 ou d'Allen et al. 2003). Les concepts d'observabilité partielle et d'observations limitées peuvent générer des recommandations utiles en matière de maintenance. En outre, l'utilisation de systèmes de contrôle automatique basés sur l'apprentissage bayésien par renforcement peut être appliquée pour diriger les actions de maintenance et d'intervention en cas d'incident qui recrutent des données de manière optimale en tenant compte des limitations des données.
Remerciements
Nous remercions le LTC Cade Saie et la subvention NSF n° 1409214 pour leur soutien financier, ainsi que Helen Patton, Steven Romig et Rajiv Ramnath pour leur soutien général à cette recherche et à d'autres recherches connexes.
Biographies des auteurs
THEODORE T. ALLEN est professeur associé au département d'ingénierie des systèmes intégrés de l'université d'État de l'Ohio. Il a obtenu son B.A. à Princeton, son M.S. à UCLA et son doctorat à l'université du Michigan (1997). Il est actuellement président de la section Social Media Analytics d'INFORMS et rédacteur en chef de la section simulation de Computers & Industrial Engineering (IF : 3.2). Il a publié plus de 60 articles dans des revues à comité de lecture et a reçu plus de 25 subventions en tant que chercheur principal, notamment de la NSF, d'ARCYBER et de GE Appliances. Ses recherches sur l'optimisation de la simulation pour l'attribution des machines à voter ont reçu une attention nationale et il a contribué à éviter à des millions d'électeurs des heures d'attente et des modifications effectives ou réelles de la législation en Caroline du Nord, dans l'Ohio et dans le Michigan. Il a également été rédacteur en chef adjoint du Journal of Manufacturing Systems et de Quality Approaches in Education et a été réviseur pour Operations Research, Technometrics et de nombreuses autres revues (allen.515@osu.edu).
ENHAO LIU est doctorant au département d'ingénierie des systèmes intégrés de l'université d'État de l'Ohio. Il a obtenu sa maîtrise à l'Ohio State University (2017) et son baccalauréat à l'Université de Jinan en génie électrique et en automatisation (2015). Il s'intéresse à la cybersécurité, à la recherche opérationnelle et à l'ingénierie de la fiabilité (liu.5045@osu.edu).
Références
Afful-Dadzie, A. et T. T. Allen. 2014. Data-driven Cyber-Vulnerability Maintenance Policies. Journal of Quality Technology 46(3):234.
Afful-Dadzie, A. et T. T. Allen. 2016. "Méthodes de cartes de contrôle pour les données de cyber-vulnérabilité autocorrélées". Quality Engineering 28(3):313-28.
Allen, T. T., 2011. Introduction à la simulation d'événements discrets et à la modélisation basée sur les agents : Voting Systems, Health Care, Military, and Manufacturing. Londres : Springer Science & Business Media.
Allen, T. et M. Bernshteyn. 2006. "Mitigating Voter Waiting Times". Chance 19(4):25-34.
Allen, T. T. K. M. et Maybin. 2004. "Using Focus Group Data to Set New Product Prices". Journal of Product & Brand Management 13(1):15-24.
Allen, T. T., L. Yu et J. Schmitz. 2003. "An Experimental Design Criterion for Minimizing Meta-model Prediction Errors Applied to Die Casting Process Design". Journal of the Royal Statistical Society : Series C (Applied Statistics), 52(1):103-117.
Allen, T. T., J. Schenk, et D. D. Woods. 2016. "An Initial Comparison of Selected Models of System Resilience". Dans Resilience Engineering Perspectives, édité par E. Hollnagel et C. Nemeth, Volume 2, 95-116. Londres : CRC Press.
Case, D. U. 2016. "Analyse de la cyberattaque contre le réseau électrique ukrainien. Washington, DC : Centre de partage et d'analyse de l'information sur l'électricité (E-ISAC).
Gauci A., S. Michelin, et M. Salles. 2017. "Relever le défi de la maintenance de la cybersécurité par la gestion des correctifs". CIRED-Open Access Proceedings Journal (1):2599-2601.
Naugle, A., M. Bernard, et I. V. Lochard. 2016. "Simulating Political and Attack Dynamics of the 2007 Estonian Cyber Attacks". In Proceedings of the 2016 Winter Simulation Conference, édité par T.M. K. Roeder et al, 3500-3509. Piscataway, New Jersey : IEEE.
Nguyen, C. K. Q., J. E. Dietz, S. Liles, V. Raskin, et J. Springer. 2015. "Cyber Defense Econometric of a Power Grid Distribution Infrastructure". In Proceedings of the 2015 Winter Simulation Conference, édité par L. Yilmaz et al, 906-911. Piscataway, New Jersey : IEEE.
Huang, D. et T. T. Allen. 2005. "Design and Analysis of Variable Fidelity Experimentation Applied to Engine Valve Heat Treatment Process Design". Journal of the Royal Statistical Society : Series C (Applied Statistics) 54(2):443-463.
Law, A. M. et W. D. Kelton. 2000. Simulation Modeling & Analysis. 3e éd. New York : McGraw-Hill. Shin J., H. Son, et G. Heo. 2015. "Développement d'un modèle de risque de cybersécurité à l'aide de réseaux bayésiens". Reliability Engineering & System Safety 134:208-217.