El desafío
por Theodore T. Allen y Enhao Liu (Universidad Estatal de Ohio)
Tal y como se presentó en la Conferencia de Simulación de Invierno de 2018
Este artículo propone un modelo de simulación de eventos discretos de una organización que mantiene hosts informáticos e incurre en varios millones de dólares en costes de mantenimiento y respuesta a incidentes. La política de mantenimiento común se denomina "out-of-sight is out-of-mind" (OSOM) porque la mayoría de los hosts están ausentes de los escaneos y son ignorados. Los hosts son "oscuros" (ausentes) porque no son accesibles (apagados o con permisos restringidos). El modelo propuesto se utiliza para comparar OSOM con alternativas que incluyen análisis mejorados que hacen visibles las vulnerabilidades de los hosts oscuros. Los resultados aclaran los aparentes beneficios de OSOM a menos que se apliquen costes indirectos por intrusiones o políticas mejoradas. Además, se aclaran los beneficios de utilizar sistemas operativos Windows y políticas mejoradas, incluyendo millones en ahorros esperados (frente a Linux).
Introducción
Los costes relacionados con la ciberseguridad son importantes a múltiples niveles, desde la política nacional e internacional hasta las redes eléctricas que conectan miles de organizaciones, pasando por los gastos dentro de las organizaciones individuales. Los modelos de eventos discretos han explorado los efectos políticos (Naugle et al. 2016). Los modelos a nivel de red eléctrica incluyen los descritos por Nguyen et al. (2015). Asimismo, los modelos de simulación de ataques incluyen a Shinet al. (2015) y Case (2016).
En nuestra propia investigación, hemos explorado modelos de procesos de decisión de Markov de gastos organizativos centrados en las evoluciones de hosts individuales (Afful-Dadzie y Allen 2014; 2016). Los hosts informáticos pueden ser ordenadores personales normales, portátiles, servidores, impresoras o incluso equipos de ejercicio. Aquí nos centramos únicamente en los dispositivos conectados a Internet que podrían verse comprometidos y que son objeto de análisis y mantenimiento. Estos dispositivos se utilizan para tareas estudiantiles, de investigación y administrativas. Estos dispositivos tienen las llamadas "vulnerabilidades", que son puntos débiles que los atacantes pueden explotar. Por ejemplo, un host puede utilizar una contraseña débil, un software con un cifrado obsoleto o un software sin suficientes comprobaciones sobre el tamaño de las entradas o salidas. Estas vulnerabilidades están clasificadas por el Instituto Nacional de Normalización de Estados Unidos (NIST) y el sistema común de puntuación de vulnerabilidades.
Aquí proponemos ampliar los datos y supuestos para el desarrollo de políticas de mantenimiento a simulaciones de eventos discretos. Esto es similar a la gestión de parches en los servicios públicos de electricidad abordada por Gauci et al. (2017), excepto que consideramos un mayor número de incidentes pasados y un surtido más amplio de políticas y tipos de host. Las ventajas de la simulación de eventos discretos incluyen formas relativamente intuitivas de incluir la creación y destrucción de hosts y recursos finitos de parcheado y respuesta a incidentes. Argumentamos que es importante tener en cuenta las cuestiones relacionadas con el "final de la vida útil" de los hosts porque, anecdóticamente, sabemos de hosts que se creían retirados y que se están utilizando y causando incidentes.
Según nuestra experiencia, una política común es exigir que el personal intente parchear o mitigar las vulnerabilidades de nivel alto o crítico en el plazo de un mes desde el momento en que se observa la vulnerabilidad en los escaneos mensuales. Esta política ignora las vulnerabilidades de nivel medio o bajo, que tienden a acumularse. Además, normalmente el 70% de los casi 50.000 hosts distintos que estudiamos no aparecían en los escaneos de un mes determinado. Esto puede ocurrir porque el host está apagado durante el escaneado o porque faltan permisos. Afful-Dadzie y Allen (2014; 2016) describen algunos métodos para imputar las vulnerabilidades que faltan en los datos de escaneado. Recientemente, disponemos de métodos que pueden predecir con gran precisión (errores del 0,05 %) las vulnerabilidades en hosts que no están presentes ("oscuras") en los escaneos mensuales.
Aquí, consideramos las implicaciones de 21 meses de transiciones observadas de mes a mes de aproximadamente 50.000 hosts. Las estimaciones de probabilidad de transición resultantes se muestran en la Tabla 1. Las probabilidades reflejan los efectos combinados de al menos cuatro factores. En primer lugar, los usuarios de los hosts añaden software constantemente y el software que ya han añadido está envejeciendo. En segundo lugar, los piratas informáticos buscan constantemente vulnerabilidades, observan el reconocimiento de las vulnerabilidades que se comunican públicamente y obtienen exploits (que a menudo también se publican libremente). En tercer lugar, los proveedores intentan constantemente parchear automáticamente su software de forma remota. En cuarto lugar, el personal intenta parchear las vulnerabilidades de acuerdo con la política de la organización con listas de vulnerabilidades obtenidas de los escaneos y los resultados de sus propias búsquedas de parches disponibles, probando los parches obtenidos para no destruir la funcionalidad, y aplicando los parches encontrados y probados (si los hay).
También en este caso consideramos sólo dos tipos de hosts. Se trata de hosts Linux y Windows para los que el usuario tiene privilegios de administrador para instalar nuevo software y el host no está controlado por administradores. (Los hosts controlados son generalmente mucho más seguros.) Aquí, nos referimos a la política de mantenimiento común en la que los hosts oscuros son ignorados como "fuera del sitio está fuera de la mente" (OSOM). Uno de los principales objetivos de este artículo es aclarar los problemas con la política OSOM y los posibles beneficios de políticas más sofisticadas.
Tabla 1: Datos de transición estimados de una universidad importante (a) hosts Linux, (b) transiciones modificadas que reflejan una informática mejorada, (c) hosts Windows y (d) cambios derivados de una informática mejorada.
(a)
| Bajo-Med. | Bajo-Med.-Oscuro | Crítico alto | Alto-Crit.-Oscuro | Comp. | Comp.-Oscuro | |
|---|---|---|---|---|---|---|
| Bajo-Med. | 0.2820 | 0.6580 | 0.0177 | 0.0413 | 0.0005 | 0.0005 |
| Bajo-Medio-Oscuro | 0.2820 | 0.6580 | 0.0177 | 0.0413 | 0.0005 | 0.0005 |
| Criterio alto | 0.1290 | 0.3010 | 0.1560 | 0.3640 | 0.0250 | 0.0250 |
| Alto-Crit.-Oscuro | 0.0000 | 0.0000 | 0.2250 | 0.7000 | 0.0250 | 0.0500 |
| Comp. | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| Comp.-Oscuro | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.8000 | 0.2000 |
| (b) | ||||||
| Alto-Crit.-Oscuro | 0.1290 | 0.3010 | 0.1560 | 0.3640 | 0.0250 | 0.0250 |
(c)
| Bajo-Med. | Bajo-Med.-Oscuro | Crit.alto | Alto-Crit.-Oscuro | Comp. | Comp.-Oscuro | |
|---|---|---|---|---|---|---|
| Bajo-Med. | 0.2760 | 0.6440 | 0.0239 | 0.0559 | 0.0001 | 0.0001 |
| Bajo-Medio-Oscuro | 0.2760 | 0.6440 | 0.0239 | 0.0559 | 0.0001 | 0.0001 |
| Criterio alto | 0.1444 | 0.3369 | 0.1554 | 0.3627 | 0.0003 | 0.0003 |
| Alto-Crit.-Oscuro | 0.0000 | 0.0000 | 0.2988 | 0.7000 | 0.0006 | 0.0006 |
| Comp. | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| Comp.-Oscuro | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.8000 | 0.2000 |
| (d) | ||||||
| Alto-Crit.-Oscuro | 0.1444 | 0.3369 | 0.1554 | 0.3627 | 0.0003 | 0.0003 |
El modo propuesto
Tamaño de la unidad y período de tiempo
Nuestro modelo de simulación de eventos discretos necesariamente especifica el número de servidores y entidades típicamente dentro del sistema (Allen 2011; Law y Kelton 2000). Observamos que una gran universidad se organiza generalmente como múltiples departamentos, en gran medida independientes, cada uno con típicamente 100 hosts. Cada organización tiene un administrador principalmente responsable de reparar vulnerabilidades y facilitar respuestas a incidentes conocidos. Por lo tanto, el modelo incluye algo más de 100 hosts (de media) durante un periodo de más de 100 años para reflejar aproximadamente los costes de mantenimiento y respuesta de una universidad. Como se señala en AffulDadzie y Allen (2016), suponemos que los costes de parcheado de vulnerabilidades son de 150 dólares de media y la respuesta a incidentes conocidos cuesta 2.000 dólares de media. Por lo tanto, los impactos de las vulnerabilidades se contabilizan pero solo en relación con los costes directos para abordar legalmente los incidentes conocidos.
Estados
Siguiendo a Afful-Dadzie y Allen (2016), categorizamos los hosts según la vulnerabilidad de mayor riesgo, por ejemplo, un host con cualquier vulnerabilidad crítica se categoriza como crítico. En la política común, los hosts de riesgo bajo y medio son generalmente ignorados. Los hosts también pueden estar comprometidos, por ejemplo, el host tiene malware que intenta contactar con el hacker o el equipo de hackers pero es interceptado por el sistema de prevención de intrusiones. Debido a que algunos hosts son "oscuros" en el escaneo y algunas intrusiones son desconocidas, consideramos estados además del estado de host basura o reciclado. Los estados incluyen combinaciones visibles y oscuras de bajo-medio, alto-crítico y comprometido. Bajo y medio y alto y crítico se emparejan porque a menudo se tratan como equivalentes en las políticas organizativas.
Nótese que conocer las vulnerabilidades o las intrusiones puede no ayudar a los objetivos percibidos de la organización. Sin embargo, la observabilidad es claramente una propiedad deseable de los sistemas "resilientes" (Allen et al. 2016). Uno de los principales objetivos de este artículo es aclarar los posibles beneficios de una mejor observabilidad.
La solución
Modelo SIMIO
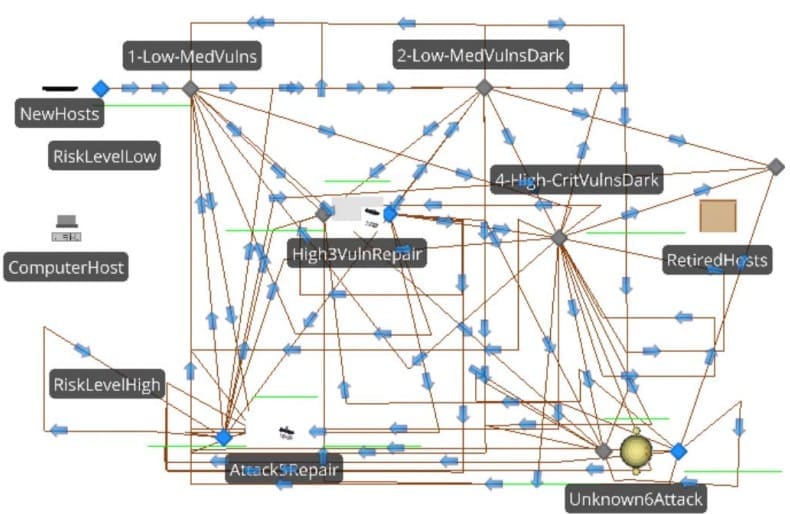
El modelo se implementa en el software SIMIO. El "NewHosts" en la parte superior izquierda de la Figura 1 a continuación es la fuente con hosts que van al nodo de vulnerabilidad baja-media donde no hay procesamiento. Esta falta de procesamiento (investigación, pruebas y aplicación de parches si existen) es una medida común de ahorro de costes en la que se ignoran las cibervulnerabilidades de baja calificación. Hasta hace poco, debido a las dificultades de inspección, muchas universidades y otras organizaciones también ignoraban en gran medida todas las cibervulnerabilidades ajenas a la red. Por lo tanto, aquí también se ignoran. Todas las rutas son "rutas temporales" fijas que corresponden a un mes.
Las ponderaciones son proporcionales a las probabilidades de la Tabla 1. Los nodos sin procesamiento corresponden a los estados 1, 2 y 4. Los servidores son los estados 3, 5 y 6. Aunque el estado de compromiso oscuro no requiere trabajo del personal interno, se utiliza un servidor para registrar la información relacionada con los costes de ese estado. El nodo de retirada está a la derecha en la Figura 1, en el que los hosts se reciclan o se envían a vertederos. En general, los hosts se crean a la izquierda y fluyen hacia la destrucción a la derecha. Pasan de estados seguros en la parte superior a la vulnerabilidad y el compromiso en la parte inferior.
Por supuesto, en el mundo real, los ordenadores residen en oficinas o cafeterías y experimentan un movimiento mínimo (a excepción de los portátiles y los teléfonos móviles). Por lo tanto, la lógica habitual de mover hosts se aplica como se indica en la Figura 2. Los hosts sí se mueven al principio y al final de sus "vidas", cuando entran en los vertederos.
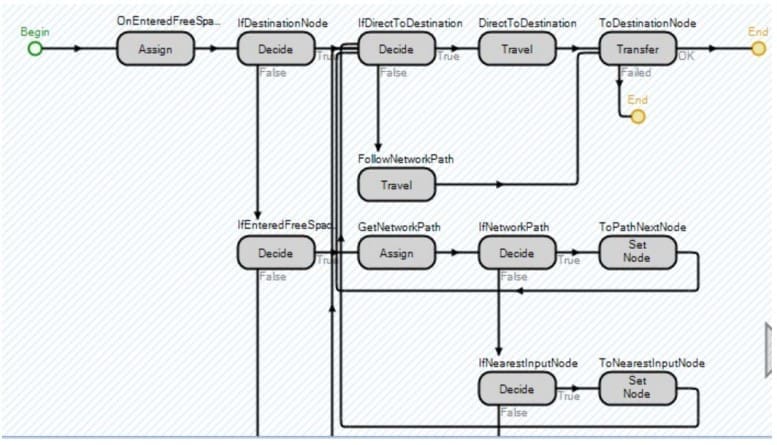
Las principales diferencias entre el modelo de la Figura 1 y el modelo de Proceso de Decisión de Markov en Afful-Dadzie y Allen (2016) son la inclusión del nacimiento y la muerte de los hosts aquí y la exploración relativamente menos exhaustiva de las políticas óptimas aquí. Uno de los principales puntos fuertes de los procesos de decisión de Markov es la capacidad de generar políticas de control óptimas. Sin embargo, la calidad de estas políticas "óptimas" está limitada por los supuestos asociados. Además, los ataques desconocidos se tienen en cuenta aquí en el modelo de simulación y no antes.
Impacto en la empresa
Resultados brutos
En la tabla 2 se muestran los resultados brutos de SIMIO. En los resultados, se utilizan 100 réplicas para mantener las medias de los intervalos de confianza del 95% por debajo del 1% de las cantidades estimadas. Los resultados incluyen "H3VRStation1" para aclarar que sólo tienen en cuenta las visitas a la estación de reparación visible y no las vulnerabilidades oscuras o desconocidas. Estos costes hipotéticos se añaden en las derivaciones del análisis de resultados para que no se deriven directamente de las simulaciones. Escenarios Linux derivados de las probabilidades de la Tabla 1(a) y (b) y Windows derivados de las probabilidades de la Tabla 1(c) y (d).
Los resultados de la Tabla 2 se refieren al número de hosts que visitan cada nodo. Visitar un nodo de reparación o de incidentes conlleva directamente un coste, ya que un miembro del personal tiene que intentar parchear las vulnerabilidades relacionadas o responder a los incidentes pertinentes. Por lo tanto, los costes del escenario son 150 $ × (N.º medio de reparaciones) + 2.000 $ × (N.º medio de incidentes).
Tabla 2. Resultados brutos de SIMIO de 100 réplicas Resultados brutos de SIMIO de 100 réplicas para el número de llegadas a las 3 estaciones clave y costes medios o previstos asociados. Los cuatro "objetos" o servidores clave son "Active5Repair" (A5R), "High3VulnRepair" (H3VR) y "Unknown6Attack" (U6A).
| Escenario | Nombre del objeto | Media | Media Anchura | Stdev. | Exp. Coste | Desv. | Scen. Totales |
|---|---|---|---|---|---|---|---|
| Linux | A5R | 1241.5 | 8.2 | 40.8 | $2,482,980 | 81,557 | - |
| Linux | H3VR | 6915.9 | 30.7 | 152.8 | $1,037,387 | 22,927 | - |
| Linux | U6A | 1529.4 | 11.1 | 55.4 | $3,058,860 | 110,719 | $6,579,227 |
| Linux No D. | A5R | 1051.4 | 6.7 | 33.4 | $2,102,700 | 66,825 | - |
| Linux No D. | H3VRStation1 | 5733.1 | 25.7 | 127.6 | $2,866,565 | 63,808 | - |
| Linux No D. | U6A | 1201.5 | 8.4 | 41.7 | $2,402,920 | 83,436 | $7,372,185 |
| Windows | A5R | 114.8 | 2.3 | 11.3 | $229,660 | 22,511 | - |
| Windows | H3VR | 8528.2 | 33.8 | 168.0 | $1,279,229 | 25,198 | - |
| Ventanas | U6A | 69.0 | 2.1 | 10.6 | $137,980 | 21,133 | $1,646,869 |
| Windows No D. | A5R | 90.5 | 2.0 | 10.0 | $180,920 | 20,049 | - |
| Windows No D. | H3VRStation1 | 5902.8 | 25.4 | 126.3 | $2,951,415 | 63,139 | - |
| Ventanas No D. | U6A | 46.5 | 1.5 | 7.6 | $93,080 | 15,102 | $3,225,415 |
| Linux Sin oscuridad | H3VRStation1 | 5733.1 | 25.7 | 127.6 | $2,866,565 | 63,808 | $7,372,185 |
| Hipótesis de Windows | H3VRStation1 | 5902.8 | 25.4 | 126.3 | $2,951,415 | 63,139 | $864,283 |
Comparación de alternativas
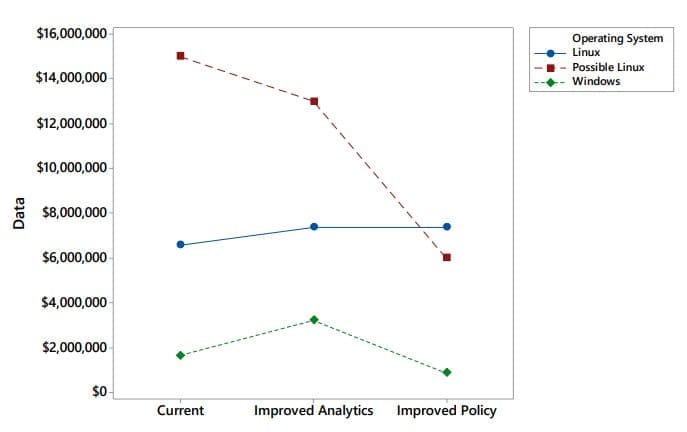
En la figura 3 se comparan seis sistemas en relación con los costes previstos. Los resultados de los sistemas Linux y Windows actuales se derivan directamente de la simulación con las entradas de la Tabla 1 y los resultados de la Tabla 2. La política denominada "analítica mejorada" para cada sistema se refiere simplemente a las probabilidades o ponderaciones procedentes de la Tabla 1(b) o la Tabla 1(d) para los sistemas operativos Linux y Windows respectivamente. Estos cambios corresponden a hacer que el estado 4 sea equivalente al estado 3 en rendimiento, de modo que se producirían operaciones de parcheado adicionales. En otras palabras, se revelan las vulnerabilidades ocultas. Esto añade 1/0,3 veces el coste del servidor en estado 3 (A3VR).
Las estimaciones del sistema "Linux posible" se basan en la consulta a un experto. Se utilizaron preguntas sobre lo que cabría esperar y lo que sería plausiblemente demasiado alto o demasiado bajo para obtener estimaciones que incluyeran razonablemente los costes de incidentes desconocidos mediante un proceso de elicitación de tipo marketing (Allen y Maybin 2004). Los posibles resultados de Linux pretenden reflejar los beneficios de conocer las vulnerabilidades de los hosts oscuros.
Las estimaciones de políticas mejoradas se basan en los resultados probables que podrían producirse si sólo se parcheasen las vulnerabilidades críticas (1/5 vulnerabilidades o menos) en los sistemas Windows. Debido a la vigorosa aplicación automática de parches, nuestros análisis a partir de procesos de decisión de Markov indican que aplicar parches a vulnerabilidades elevadas en determinados tipos de sistemas Windows no es rentable (Afful-Dadzie y Allen 2016). Sin embargo, es casi seguro que la aplicación de parches a vulnerabilidades críticas en hosts oscuros reportaría beneficios. Por lo tanto, algunos de los resultados de la figura 3 se refieren a resultados de simulación y otros son estimaciones de opiniones de expertos obtenidas.
Conclusiones y trabajo futuro
Este artículo propone un modelo de simulación de eventos discretos para predecir los costes de parcheado y los costes de los incidentes. Los modelos se basan en cientos de miles de transiciones registradas. Sin embargo, también hay extrapolaciones considerables que incluyen el coste efectivo de las políticas mejoradas o de las pérdidas que incluyen incidentes desconocidos. Con estas limitaciones, surgen las siguientes conclusiones:
- Los hosts Windows requieren costes de mantenimiento sustancialmente menores en nuestro conjunto de datos y predicciones de simulación que los hosts Linux. Esto supone que los propietarios de los hosts tenían privilegios de administrador, lo que hace que su funcionamiento sea relativamente arriesgado. Sin embargo, es probable que la aplicación de parches automáticos llevada a cabo por Microsoft esté asociada a unos costes de mantenimiento organizativos más bajos.
- Hacer visibles los hosts Windows oscuros con análisis mejorados no parece estar justificado desde el punto de vista de los costes. Esto se debe a que el coste de tratar con el 70% de las vulnerabilidades ignoradas por la política "fuera del sitio, fuera de la mente" no se vería compensado por la reducción de incidentes conocidos. Sin embargo, si las pérdidas para la sociedad en general pudieran estimarse con precisión, entonces la reducción de incidentes por parchear las vulnerabilidades oscuras podría compensarse.
- Hacer visibles los hosts Linux oscuros con análisis mejorados tiene un coste aproximadamente justificado y probablemente beneficiaría al sistema con una mayor resistencia y beneficios sociales.
- Hacer visibles los hosts oscuros de todo tipo probablemente esté justificado en términos de costes si los análisis mejorados se combinan con una política mejorada. Por ejemplo, en el caso de los hosts Windows, podrían ignorarse muchas o todas las vulnerabilidades elevadas, ya que la aplicación automática de parches probablemente se ocupe de muchas de ellas, pero las vulnerabilidades críticas de los hosts oscuros podrían predecirse y parchearse para reducir los costes de los incidentes.
Las principales limitaciones del modelo propuesto se refieren a características no compatibles. Los metamodelos multifidelidad podrían proporcionar una capacidad prescriptiva mejorada (por ejemplo, utilizando los métodos de planificación y análisis de Allen y Bernstheyn 2005 o Allen et al. 2003). Los conceptos de observabilidad parcial y observaciones limitadas pueden generar recomendaciones de mantenimiento útiles. Asimismo, el uso de sistemas de control automático basados en el aprendizaje bayesiano por refuerzo puede aplicarse para dirigir las acciones de mantenimiento y respuesta a incidentes que reclutan datos de forma óptima atendiendo a las limitaciones de los mismos.
Agradecimientos
Agradecemos a LTC Cade Saie y NSF Grant # 1409214 por el apoyo financiero y a Helen Patton, Steven Romig, y Rajiv Ramnath por el apoyo general para esta investigación y otras relacionadas.
Biografías de los autores
THEODORE T. ALLEN es profesor asociado en el departamento de Ingeniería de Sistemas Integrados de la Universidad Estatal de Ohio. Obtuvo su licenciatura en Princeton, su máster en UCLA y su doctorado en la Universidad de Michigan (1997). Actualmente es presidente de la sección Social Media Analytics de INFORMS y editor del área de simulación de Computers & Industrial Engineering (IF: 3.2). Ha publicado más de 60 artículos arbitrados y ha recibido más de 25 subvenciones como IP, incluidas las de NSF, ARCYBER y GE Appliances. Su investigación sobre la optimización de la simulación para la asignación de máquinas de votación ha recibido atención nacional y ha contribuido a que millones de votantes eviten horas de espera y cambios efectivos o reales de la ley en Carolina del Norte, Ohio y Michigan. También ha sido editor asociado de Journal of Manufacturing Systems y Quality Approaches in Education y revisor de Operations Research, Technometrics y muchas otras revistas (allen.515@osu.edu).
ENHAO LIU es estudiante de doctorado en el departamento de Ingeniería de Sistemas Integrados de la Universidad Estatal de Ohio. Obtuvo su maestría en la Universidad Estatal de Ohio (2017) y su licenciatura en Ingeniería Eléctrica y Automatización en la Universidad de Jinan (2015). Sus intereses están relacionados con la ciberseguridad, la investigación de operaciones y la ingeniería de fiabilidad (liu.5045@osu.edu).
Referencias
Afful-Dadzie, A. y T. T. Allen. 2014. Políticas de mantenimiento de la cibervulnerabilidad basadas en datos. Journal of Quality Technology 46(3):234.
Afful-Dadzie, A. y T. T. Allen. 2016. "Métodos de gráficos de control para datos de vulnerabilidad cibernética autocorrelacionados". Quality Engineering 28(3):313-28.
Allen, T. T., 2011. Introducción a la Simulación de Eventos Discretos y Modelado Basado en Agentes: Voting Systems, Health Care, Military, and Manufacturing. Londres: Springer Science & Business Media.
Allen, T. y M. Bernshteyn. 2006. "Mitigating Voter Waiting Times". Chance 19(4):25-34.
Allen, T. T. K. M. y Maybin. 2004. "Using Focus Group Data to Set New Product Prices". Journal of Product & Brand Management 13(1):15-24.
Allen, T. T., L. Yu y J. Schmitz. 2003. "An Experimental Design Criterion for Minimizing Meta-model Prediction Errors Applied to Die Casting Process Design". Journal of the Royal Statistical Society: Series C (Applied Statistics), 52(1):103-117.
Allen, T. T., J. Schenk y D. D. Woods. 2016. "Una comparación inicial de modelos seleccionados de resiliencia del sistema". En Resilience Engineering Perspectives, editado por E. Hollnagel y C. Nemeth, Volume 2, 95-116. London: CRC Press.
Case, D. U. 2016. "Análisis del ciberataque a la red eléctrica ucraniana". Washington, DC: Centro de Análisis e Intercambio de Información sobre Electricidad (E-ISAC).
Gauci A., S. Michelin, y M. Salles. 2017. "Abordando el reto del mantenimiento de la ciberseguridad a través de la gestión de parches". CIRED-Periódico de Actas de Acceso Abierto (1):2599-2601.
Naugle, A., M. Bernard, y I. V. Lochard. 2016. "Simulación de la dinámica política y de ataque de los ciberataques estonios de 2007". En Proceedings of the 2016 Winter Simulation Conference, editado por T.M. K. Roeder et al., 3500-3509. Piscataway, Nueva Jersey: IEEE.
Nguyen, C. K. Q., J. E. Dietz, S. Liles, V. Raskin y J. Springer. 2015. "Ciberdefensa econométrica de una infraestructura de distribución de la red eléctrica". En Proceedings of the 2015 Winter Simulation Conference, editado por L. Yilmaz et al., 906-911. Piscataway, Nueva Jersey: IEEE.
Huang, D. y T. T. Allen. 2005. "Design and Analysis of Variable Fidelity Experimentation Applied to Engine Valve Heat Treatment Process Design". Revista de la Real Sociedad Estadística: Series C (Applied Statistics) 54(2):443-463.
Law, A. M. y W. D. Kelton. 2000. Simulation Modeling & Analysis. 3rd ed. Nueva York: McGraw-Hill. Shin J., H. Son y G. Heo. 2015. "Desarrollo de un modelo de riesgo de ciberseguridad utilizando redes bayesianas". Reliability Engineering & System Safety 134:208-217.