
Moderne Unternehmensabläufe erfordern eine beispiellose Transparenz der Geschäftsabläufe und Möglichkeiten zur Prozessoptimierung. Digitale Zwillinge für Prozesse erfüllen diesen Bedarf durch ausgefeilte virtuelle Nachbildungen, die die betrieblichen Aktivitäten widerspiegeln und bei der Umsetzung Effizienzsteigerungen von bis zu 15 % sowie Kostensenkungen zwischen 20 und 30 % ermöglichen. Aktuelle Einführungsmuster zeigen, dass 70 % der Technologie- F ührungskräfte auf C-Level in großen Unternehmen aktiv nach Digital-Twin-Lösungen suchen und in diese investieren. Die globale Marktentwicklung spiegelt diese Dynamik wider: Die jährlichen Wachstumsraten liegen bei fast 60 %, und Prognosen gehen von einem Marktvolumen von 73,5 Milliarden US-Dollar bis 2027 aus.
Dieser Blogbeitrag untersucht das gesamte architektonische Rahmenwerk der Technologie für digitale Prozesszwillinge – von den grundlegenden Datenschichten über Integrationssysteme bis hin zu Benutzeroberflächen. Sie erfahren, wie diese technischen Komponenten zusammenwirken, um virtuelle Prozessmodelle zu erstellen, die über die herkömmliche Überwachung hinausgehen und ein vorausschauendes, simulationsgestütztes Prozessmanagement ermöglichen.
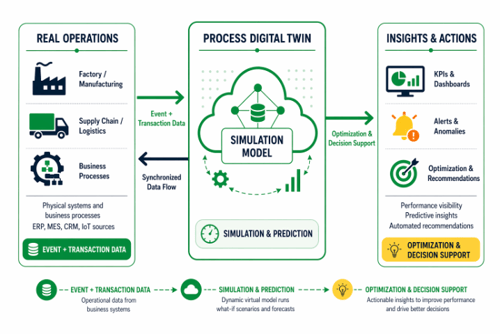
Die Technologie des digitalen Prozesszwillings verstehen
Was ist ein digitaler Prozesszwilling?
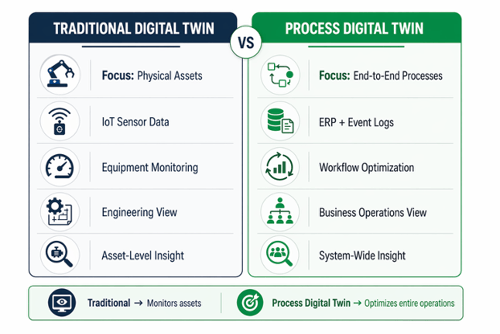
Ein Prozess-Digital-Twin ist ein umfassendes digitales Modell, das den gesamten Geschäftsbetrieb abbildet – nicht nur die physischen Anlagen. Im Gegensatz zu herkömmlichen Digital-Twins, die einzelne Anlagen oder Produkte überwachen, erstellen Prozess-Digital-Twins dynamische virtuelle Nachbildungen kompletter Arbeitsabläufe, einschließlich Ressourcenzuweisung, Materialflüsse, Geschäftsregeln, Entscheidungslogik und relevanter Systeminteraktionen, um den Prozessablauf und die damit verbundenen Ergebnisse bis in die Zukunft hinein genau nachzubilden
Laut IBM ermöglichen digitale Zwillinge eine kontinuierliche Überwachung, Simulation und Analyse über den gesamten Lebenszyklus hinweg, vom Entwurf bis zur Stilllegung. Das Digital Twin Consortium definiert diese Technologie technisch als eine integrierte, datengesteuerte virtuelle Darstellung realer Entitäten und Prozesse mit synchronisierter Interaktion bei einer festgelegten Frequenz und Genauigkeit.
Die Technologieder Prozess-Digital-Twins zeichnet sich durch eine umfassende Datenextraktion aus Unternehmenssystemen aus und beschränkt sich nicht allein auf die Überwachung durch physische Sensoren. Diese virtuellen Modelle erfassen vollständige betriebliche Arbeitsabläufe anhand von Ereignisprotokollen und Transaktionsaufzeichnungen sowohl für statische als auch für dynamische Daten und ermöglichen es Unternehmen, Engpässe und Ineffizienzen über gesamte Geschäftsprozesse hinweg in Echtzeit zu identifizieren.
Virtuelle Darstellung von Geschäftsprozessen
Prozess-Digital-Twins stellen einen bidirektionalen Datenfluss zwischen virtuellen Darstellungen und physischen Abläufen her. Diese bidirektionale Kommunikation unterscheidet sie von herkömmlichen Überwachungssystemen, die nur eine einseitige Transparenz bieten. Das virtuelle Modell geht über die passive Beobachtung hinaus und beeinflusst aktiv Entscheidungen sowie löst automatisierte Aktionen aus.
Dieser bidirektionale Datenfluss schafft kontinuierliche Rückkopplungsschleifen. Veränderungen in der virtuellen oder physischen Umgebung spiegeln sich sofort in der jeweils anderen wider, was Musteranalysen, Simulationsmodelle und Entscheidungsunterstützungssysteme ermöglicht, die den Betrieb direkt beeinflussen. Untersuchungen von McKinsey zeigen, dass Unternehmen die Geschwindigkeit ihrer Entscheidungsfindung mithilfe von Erkenntnissen aus digitalen Zwillingen um bis zu 90 % steigern können.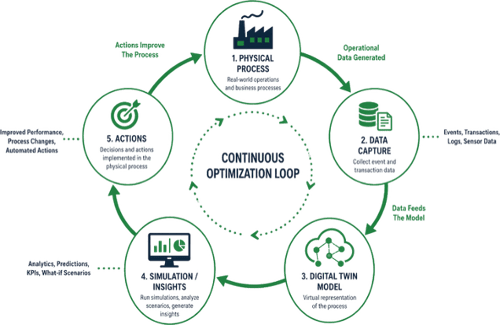
Echtzeit- vs. Nahe-Echtzeit-Aktualisierungen
Die zeitlichen Eigenschaften der Datensynchronisation haben erhebliche Auswirkungen auf Beispiele für digitale Zwillinge in Prozessen und deren praktische Einsatzszenarien. Echtzeit-Digitale Zwillinge verarbeiten eingehende Daten sofort oder in Intervallen von weniger als einer Sekunde, spiegeln kontinuierlich den aktuellen Systemzustand wider und ermöglichen sofortige operative Reaktionen. Laut einer Studie in ScienceDirect sind in vielen Anwendungen Reaktionszeiten in der Größenordnung von Millisekunden bis Sekunden wünschenswert. In industriellen Fertigungsprozessen, in denen die Echtzeitüberwachung Sicherheit und betriebliche Effizienz gewährleistet, können Reaktionszeiten von 100 Millisekunden oder weniger angestrebt werden.
Praxisbeispiel: Eine Fertigungslinie, die Vibrationen an Anlagen erkennt, die auf einen drohenden Ausfall hindeuten, erfordert eine Echtzeitverarbeitung (unter 100 ms), um kostspielige Schäden zu vermeiden. Umgekehrt funktioniert ein Digital Twin für die Lieferkette, der Lieferrouten optimiert, effektiv mit stündlichen Aktualisierungen, da Routenentscheidungen keine Präzision im Sekundenbruchteil erfordern.
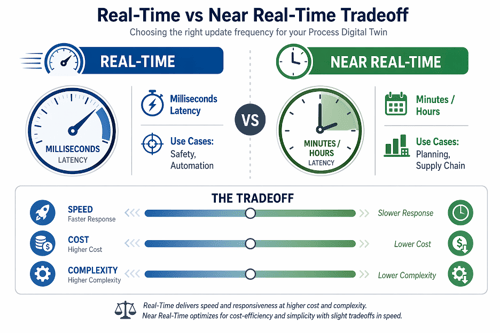
Echtzeitsysteme erweisen sich als unverzichtbar für kritische Betriebsabläufe, bei denen Verarbeitungsverzögerungen zu betrieblichen Risiken oder finanziellen Verlusten führen können. Industrielle Sicherheitssysteme, autonome Betriebsabläufe und die Optimierung von Ampelsystemen erfordern eine sofortige Datenverarbeitung und Reaktionsfähigkeit. Nahe-Echtzeit-Ansätze eignen sich gut für die Überwachung der Anlagenleistung, Stadtplanungssysteme und die Wartungsplanung, wo Entscheidungen keine Reaktionszeiten im Bruchteil einer Sekunde erfordern.
Ein ausgewogener Ansatz erweist sich bei Unternehmensimplementierungen oft als am praktischsten: Dabei werden Echtzeit-Aktualisierungen für geschäftskritische Abläufe genutzt, während für Planungs- und Optimierungsfunktionen eine Nahe-Echtzeit-Verarbeitung zum Einsatz kommt. Diese hybride Strategie gewährleistet die Skalierbarkeit des Systems, ohne dass übermäßige Infrastrukturkosten entstehen. Echtzeitsysteme erfordern hohe Bandbreite, geringe Latenz und skalierbare Verarbeitungskapazitäten, was die Anforderungen an die Infrastruktur und die betriebliche Komplexität erheblich erhöht.
Diese betrieblichen Merkmale – bidirektionaler Datenfluss, Echtzeit-Synchronisation und umfassende Datenintegration – erfordern sorgfältig aufeinander abgestimmte Architekturebenen. Die Infrastruktur unterstützt die Datenverarbeitung, die wiederum die Analyse-Engines speist, welche wiederum die Benutzeroberflächen antreiben – alles geschützt durch integrierte Sicherheitsmaßnahmen. Diese vernetzte Struktur ist der Grund, warum eine erfolgreiche Implementierung eine systematische Architekturplanung erfordert.
Architekturebenen: Die vollständige Struktur
Die Architektur des digitalen Zwillings basiert auf miteinander verbundenen Schichten, die zusammenwirken, um rohe Betriebsdaten in verwertbare Erkenntnisse umzuwandeln. Das Verständnis dieser Struktur verdeutlicht, wie Daten von der Erfassung über die Analyse bis hin zur Visualisierung fließen:
Drei zentrale Säulen der Architektur:
-
Grundlagenschicht (Infrastruktur + Datenverarbeitung): Rechenressourcen und Datenpipelines, die Informationen aus Unternehmenssystemen erfassen, speichern und synchronisieren
- Intelligenzschicht (Geschäftslogik): Analyse-Engines, Simulationswerkzeuge und KI-Funktionen, die Daten verarbeiten und Prognosen erstellen
- Interaktionsschicht (Darstellung + Sicherheit): Benutzeroberflächen, Dashboards und Sicherheitsframeworks, die einen sicheren und umsetzbaren Zugriff ermöglichen
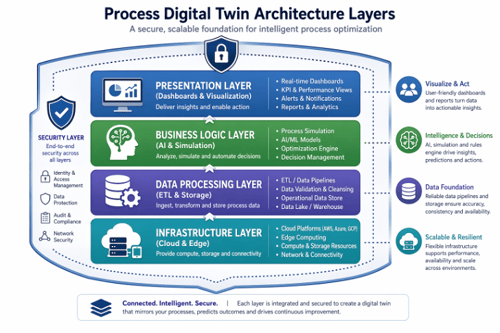
Zwar weisen verschiedene Implementierungen unterschiedliche architektonische Tiefen auf, doch bleibt diese grundlegende Struktur bei allen Plattformen für digitale Zwillinge von Prozessen konsistent. In den folgenden Abschnitten wird jede Schicht im Detail untersucht und anschließend gezeigt, wie bestimmte Komponenten – Datentypen, Integrationswerkzeuge und Modellierungsfunktionen – innerhalb dieses Rahmens funktionieren.
Grundlagenschicht: Infrastruktur und Datenmanagement
Die Basisschicht verbindet die Recheninfrastruktur mit Datenverarbeitungsfunktionen und bildet so das operative Rückgrat von Prozess-Digital-Twin-Systemen.
Infrastrukturarchitektur
Hybride Konfigurationen, die Cloud- und On-Premise-Elemente kombinieren, bieten die für einen kontinuierlichen Betrieb erforderliche Flexibilität. Cloud-Dienste übernehmen Analyseaufgaben und speichern die umfangreichen Datenmengen, die digitale Zwillinge generieren, während die physische Infrastruktur – Netzwerkrouter, IoT-Sensorarrays und Edge-Computing-Server – die Hardware-Grundlage bildet. Die Infrastruktur muss eine hochfrequente Datenübertragung unter Verwendung von Protokollen wie MQTT, OPC UA oder Apache Kafka unterstützen, um Telemetriedaten effektiv zu streamen.
Datenverarbeitung und -speicherung
Die Datenschicht verwaltet die Erfassung, Bereinigung, Synchronisierung und strukturelle Aufbereitung von Informationen aus physischen Umgebungen. Die Speicherarchitektur verfolgt einen dualen Ansatz: Zeitreihendatenbanken (wie InfluxDB) erfassen hochfrequente Sensordaten und Betriebskennzahlen, während Data-Lake-Lösungen (wie Snowflake oder Databricks) riesige historische Datensätze für Trendanalysen und das Training von Machine-Learning-Modellen speichern. So entsteht ein umfassendes Informationsökosystem, das sowohl die Echtzeitüberwachung als auch langfristige Analysen unterstützt.
Integration und Konnektivität
Unternehmensdaten sind über voneinander getrennte Systeme verstreut und erfordern eine ausgefeilte Integration. Unternehmenssystem-Konnektoren stellen grundlegende Schnittstellen bereit und erfassen Betriebsdaten aus ERP-, CRM-, MES-, IoT- und Cloud-Systemen sowie aus betrieblichen Quellen durch bidirektionale Synchronisation. Datenpipelines unterstützen die Erfassung nahezu in Echtzeit und in einigen Fällen sogar in Echtzeit unter Einhaltung der erforderlichen Latenzvorgaben, während API-Gateways einheitliche Zugangspunkte bereitstellen, die Authentifizierung, Routing und Kommunikationsprotokolle für Microservices verwalten.
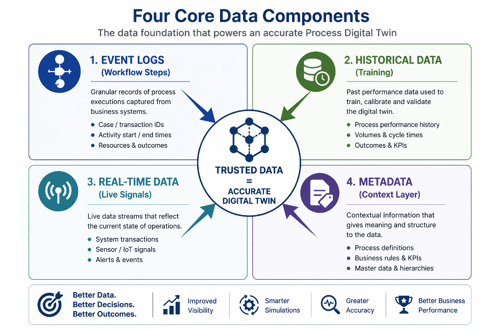
Datenbasis: Was den Digital Twin speist
Prozess-Digital-Twins benötigen drei wesentliche Datentypen, die zusammenwirken, um genaue virtuelle Abbildungen zu erstellen:
|
Datentyp |
Zweck |
Wichtigste Quellen |
Kritischer Wert |
|
Ereignisprotokolle sowie statische und dynamische Transaktionsdaten |
Erfassung aller Geschäftsaktivitäten mit Zeitstempeln, Akteuren und Ressourcen |
ERP-Systeme, Fertigungssteuerungssysteme, CRM-Plattformen, Finanzsysteme |
Ermöglicht die automatisierte Prozesserkennung und die Rekonstruktion virtueller Workflows/Modelle aus Unternehmensdaten |
|
Historische Transaktions- und Leistungsaufzeichnungen |
Legen Sie Basiswerte fest, stellen Sie Testdaten bereit und trainieren Sie Vorhersagemodelle |
Durchsatzmessungen, Zykluszeiten, Servicemetriken, Ausfallereignisse, Wartungsprotokolle |
Validierung von Digital-Twin-Modellen und Trendanalysen |
|
Echtzeit-Sensordaten |
Kontinuierliche Aktualisierung der aktuellen Zustände |
IoT-Geräte zur Erfassung von Temperatur, Druck, Vibration, Zykluszeiten und Betriebszuständen |
Liefert die Live-Datenströme, die dafür sorgen, dass digitale Zwillinge mit den physischen Abläufen synchronisiert bleiben |
Die semantische Ebene
Metadaten wandeln diese Rohmesswerte in aussagekräftige Informationen um. Anlagenkennungen, Standort-Tags und Links zu Dokumentationen stellen Verbindungen zwischen Messwerten und bestimmten Komponenten, Betriebsbedingungen und historischen Trends her – und gewährleisten so eine korrekte Interpretation im gesamten System.
Intelligenzebene: Analytik und Simulation
Die Intelligenzebene wandelt verarbeitete Daten mithilfe von drei integrierten Funktionen in vorausschauende Erkenntnisse um:
1. Prozesserkennung und -modellierung
Automatisierte Process-Mining-Software extrahiert Betriebsparameter direkt aus Ereignisprotokollen und erfasst dabei Fallankunftsraten, Aktivitätsdauern, Weiterleitungswahrscheinlichkeiten und Anforderungen an die Ressourcenzuweisung. Erkennungsalgorithmen decken Kontrollflussmodelle mithilfe von Petri-Netzen, Prozessbäumen und BPMN-Frameworks auf und ermöglichen so eine Analyse aus verschiedenen Perspektiven in den Bereichen Zeit, Finanzen, Ressourcen und Entscheidungsfindung.
Zentralisierte Wissensrepositorien erfassen umfassende Systembeschränkungen, Geschäftsregeln und Betriebslogik innerhalb integrierter Simulationsmodelle. Leistungsbenchmarking legt operative Basiskennzahlen fest, um die aktuelle Systemleistung zu bewerten und genaue Vorhersagen zu generieren. Unternehmen überwachen Schlüsselkennzahlen anhand festgelegter Benchmarks, um operative Abweichungen zu identifizieren und Verbesserungsmöglichkeiten sofort zu bewerten.
2. Simulation und Szenariotests
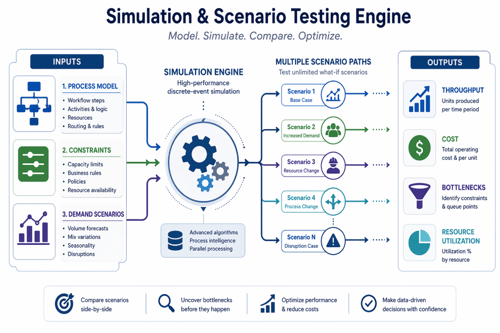
Die diskrete Ereignissimulation bildet den Systembetrieb durch die Modellierung sequenzieller Ereignisse nach und ermöglicht es Prozesssimulationsmodellen, Tausende virtueller Instanzen unter Einbeziehung tatsächlicher Zeitverteilungen, Ressourcenkapazitätsbeschränkungen und Ankunftsmuster auszuführen – wodurch quantitative Prognosen zu Zykluszeiten, Durchsatzraten, Ressourcenauslastung und Betriebskosten bereits vor der Umsetzung in der Praxis bereitgestellt werden. Die unbegrenzte Szenariosimulation ermöglicht das Testen von Prozessänderungen, Anlagenumstellungen und Personalanpassungen, ohne die Produktion zu stören.
Anwendungen mit digitalen Zwillingen ermöglichen eine Risikoanalyse durch die virtuelle Modellierung von Lieferunterbrechungen, Bestandsengpässen und Marktvolatilitätsszenarien. Die Auswirkungsmodellierung hilft Unternehmen dabei, die spezifischen Schritte zu verstehen, die erforderlich sind, um die operative Widerstandsfähigkeit über verschiedene Geschäftsfunktionen hinweg zu erhöhen – beispielsweise durch die Modellierung von Cashflow-Szenarien im Finanzbereich, die Vorhersage von Einkaufspreisschwankungen durch die Beschaffungsabteilungen und die Analyse der Bearbeitungszeitanforderungen durch Auftragsmanagementsysteme.
3. KI-gesteuerte Optimierung
Algorithmen des maschinellen Lernens ermöglichen Vorhersagefunktionen, wobei umfassende historische Daten als Trainingsgrundlage dienen. KI-gestützte Modelle zur Ressourcenoptimierung ermitteln optimale Zuweisungsstrategien, Planungsparameter und Durchsatzkapazitäten durch kontinuierliches Lernen aus historischen, Echtzeit-Zustandsdatenströmen sowie aus synthetischen Trainingsdaten, die von validierten Prozesssimulationsmodellen generiert werden. Die szenariobasierte Optimierung entwickelt und vergleicht mehrere betriebliche Ansätze, um optimale Strategien zur Bewältigung sich ändernder Anforderungen und Einschränkungen zu ermitteln.
Interaktionsschicht: Visualisierung und Sicherheit
Benutzeroberflächen und Dashboards
Effektive Dashboards bestehen aus sechs wesentlichen Elementen, die zusammenwirken:
-
Prozessvisualisierung, die dynamische Workflow-Zustände durch farbcodierte, animierte Darstellungen anzeigt (z. B. grün für reibungslosen Betrieb, gelb für sich abzeichnende Engpässe, rot für kritische Einschränkungen)
- Prädiktive Leistungsindikatoren, die statt einfacher Messungen des „aktuellen Durchsatzes“ den „Durchsatztrend mit 4-Stunden-Prognose“ oder die „Kapazitätsauslastung mit Engpasswahrscheinlichkeit“ anzeigen
- Warnsysteme mit progressiver Eskalation – dezente visuelle Hinweise bei geringfügigen Abweichungen, auffällige Warnungen bei sich abzeichnenden Problemen, dringende Benachrichtigungen bei kritischen Situationen
- Tools zum Szenariovergleich zur Bewertung betrieblicher Alternativen
- Interaktive Steuerelemente zur Untersuchung von „Was-wäre-wenn“-Szenarien
- Rollenbasierte Anpassung, die sicherstellt, dass Mitarbeiter in der Produktion eine detaillierte Aufgabenabfolge zur Ausführung jeder Aufgabe erhalten, während Führungskräfte übergeordnete Zusammenfassungen mit Kosten- und Leistungsdetails einsehen können
Sicherheits- und Governance-Rahmenwerk
Da bis zu 79 % der Unternehmen Cybersicherheit als ein zentrales Anliegen bei der Implementierung von Digital Twins betrachten, muss Sicherheit bereits in der Architektur berücksichtigt werden – und darf kein nachträglicher Einfall sein.
Dreistufiger Sicherheitsansatz:
1. Zugriffskontrolle
Die rollenbasierte Zugriffskontrolle (RBAC) schränkt den Systemzugriff anhand von Benutzerrollen ein. Laut Esri klassifizieren Organisationen Daten nach Vertraulichkeitsstufen:
-
Betrachter: Lesezugriff
- Mitwirkende: Eingeschränkte Bearbeitungsrechte
- Außendienstmitarbeiter: Aufgabenspezifische mobile Daten
- Ersteller: Erstellung innerhalb zugewiesener Grenzen
Blockchain-basierte Smart Contracts automatisieren den Entzug von Zugriffsrechten bei Rollenwechseln.
2. Datenschutz
-
End-to-End-Verschlüsselung für alle Übertragungen
- Multi-Faktor-Authentifizierung (MFA) für den Systemzugriff
- Einhaltung der Anforderungen der DSGVO/HIPAA
- Datenverschlüsselung bei der Übertragung (TLS 1.2+) und im Ruhezustand (AES 256)
- Einhaltung der ISO 27000- und FedRAMP-Standards
3. Audit-Mechanismen
Unveränderliche Prüfpfade zeichnen jede Aktion auf und erstellen so transparente Verlaufsprotokolle über Zugriffe, Änderungen und Systemanpassungen, die für die Einhaltung gesetzlicher Vorschriften und die Rechenschaftspflicht unerlässlich sind.
Laut KPMG müssen Governance-Rahmenwerke bereits in einer frühen Phase der Architekturplanung klare Rollen, Verantwortlichkeiten und Prozesse definieren, anstatt Compliance-Maßnahmen später mit erheblichem Kostenaufwand nachträglich einzubauen.
Erstellen Ihres ersten digitalen Zwillings für einen Prozess
Der Weg vom Verständnis der Architektur zur praktischen Umsetzung erfordert eine systematische Methodik, die kostspielige Fehltritte und Ressourcenverschwendung verhindert. Unternehmen müssen die Entwicklung eines digitalen Prozesszwillings in strukturierten Phasen angehen, die auf zuvor etablierten grundlegenden Datenkomponenten und Integrationsfähigkeiten aufbauen.
Auswahl des richtigen Prozesses
Die Prozessauswahl ist die entscheidende erste Entscheidung, die über den Erfolg der Umsetzung bestimmt. Unternehmen sollten Prozesse mit klaren Zielen und messbaren Ergebnissen ins Visier nehmen. Der anfängliche Fokus sollte auf der Festlegung konkreter Leistungsziele liegen, sei es die Minimierung von Ausfallzeiten durch vorausschauende Instandhaltung oder die Optimierung des Patientenflusses in Gesundheitseinrichtungen. Der Einstieg über die Überwachung einfacher Komponenten oder einzelner IoT-Geräte bietet wichtige praktische Erfahrungen, bevor auf größere, komplexere Systeme ausgeweitet wird.
Eine erfolgreiche Prozessauswahl erfordert die Bewertung der Datenverfügbarkeit, der Einbindung der Beteiligten und der potenziellen Auswirkungen auf das Geschäft. Prozesse mit klar definierten Grenzen, bestehenden Mechanismen zur Datenerfassung und eindeutigen Leistungskennzahlen bieten die höchste Wahrscheinlichkeit für eine erfolgreiche Implementierung eines Digital Twin.
Definition der Datenanforderungen
Die Datenarchitektur bildet die Grundlage, auf der präzise virtuelle Abbildungen beruhen. Unternehmen müssen Rahmenbedingungen schaffen, um Informationen von Sensoren, Betriebssystemen und Umgebungsmonitoren zu erfassen, zu validieren und zu integrieren. Diese Phase erfordert eine sorgfältige Planung der Protokolle für die Datenvorverarbeitung, -bereinigung und -synchronisation. Echtzeit-Datenströme enthalten häufig Rauschen, fehlende Werte oder zeitliche Inkonsistenzen, die von den Rahmenwerken behoben werden müssen, bevor die Informationen an virtuelle Modelle weitergeleitet werden. Erfolgreiche digitale Zwillinge sind auf eine gründliche Datenerfassung aus mehreren Quellen angewiesen, um die Genauigkeit zu gewährleisten.
In der Phase der Datenanforderungen sollten Qualitätsvereinbarungen festgelegt werden, die Standards hinsichtlich Aktualität, Vollständigkeit und Genauigkeit festlegen. Abtastraten, Methoden zur Zeitsynchronisation und Richtlinien zum Umgang mit fehlenden Daten gewährleisten einheitliche Messintervalle über alle überwachten Anlagen und Standorte hinweg.
Auswahl des Technologie-Stacks
Bei der Technologieauswahl sollte Interoperabilität im Vordergrund stehen, damit verschiedene Systeme Daten ohne Informationsverlust austauschen können. Die Auswahl der Komponenten muss die tatsächlichen Geschäftsziele unterstützen und sich gleichzeitig in bestehende Unternehmenssysteme wie ERP- oder CRM-Plattformen integrieren lassen. Unternehmen sollten fortlaufende Schulungen in den Bereichen maschinelles Lernen, IoT-Integration und fortgeschrittene Analysefunktionen einplanen.
Bei der Entscheidung für einen Technologie-Stack muss ein Gleichgewicht zwischen den aktuellen betrieblichen Anforderungen und den zukünftigen Skalierbarkeitsanforderungen gefunden werden. Cloud-native Architekturen bieten oft die für die iterative Entwicklung erforderliche Flexibilität und unterstützen gleichzeitig die hochfrequente Datenübertragung, die für den Echtzeitbetrieb von Digital Twins notwendig ist.
Validierung und Feinabstimmung
Die Modellvalidierung anhand historischer Daten legt Genauigkeits-Baselines für virtuelle Darstellungen fest. Simulationen sollten das tatsächliche Systemverhalten innerhalb akzeptabler Fehlergrenzen vorhersagen. Bei Abweichungen zwischen virtueller und physischer Leistung müssen Unternehmen ihre Modelle so lange verfeinern, bis sie den realen Betrieb zuverlässig widerspiegeln.
Die Validierungsphase erfordert systematische Tests in verschiedenen Betriebsszenarien, um eine robuste Modellleistung sicherzustellen. Mechanismen zur kontinuierlichen Überwachung und Anpassung ermöglichen eine fortlaufende Kalibrierung, während sich Geschäftsprozesse weiterentwickeln und neue Datenmuster entstehen.
Fazit
Die Architektur des digitalen Zwillings für Prozesse wird verständlich, wenn Unternehmen ihre fünfschichtige Struktur begreifen: Infrastruktur zur Bereitstellung von Rechenressourcen, Datenverarbeitung zur Verwaltung der Erfassung und Speicherung, Geschäftslogik zur Ermöglichung von Analysen und Simulationen, Darstellung zur Bereitstellung von Dashboards und Visualisierungen sowie Sicherheit zum Schutz aller Komponenten. Innerhalb dieser Schichten arbeiten die in diesem Artikel untersuchten spezifischen Komponenten – von Ereignisprotokollen und Sensordaten über Tools zur Prozesserkennung und Simulations-Engines bis hin zu interaktiven Dashboards – zusammen, um virtuelle Darstellungen zu erstellen, die Effizienzsteigerungen von bis zu 15 % und Kostensenkungen zwischen 20 und 30 % ermöglichen .
Eine erfolgreiche Implementierung beginnt damit, zu verstehen, wo Ihre technischen Fähigkeiten in dieses Architekturkonzept passen. Die Datenqualität bildet die entscheidende Grundlage auf der Datenverarbeitungsschicht, während die Simulationsgenauigkeit von den Modellierungskomponenten der Geschäftslogikschicht abhängt. Bei der Technologieauswahl sollte die Kompatibilität mit bestehenden Unternehmenssystemen im Vordergrund stehen, damit Ihr Unternehmen auf aktuellen Infrastrukturinvestitionen aufbauen kann, anstatt umfassende Plattformersetzungen vornehmen zu müssen.
Unternehmen, die digitale Zwillinge von Prozessen nach diesem mehrschichtigen Architekturansatz erstellen, erschließen sich die Vorhersagemöglichkeiten und betrieblichen Erkenntnisse, die Wettbewerbsvorteile schaffen. Das hier vorgestellte strukturierte Rahmenwerk versetzt Entscheidungsträger in die Lage, fundierte Technologieentscheidungen zu treffen, die auf die betrieblichen Anforderungen und Geschäftsziele abgestimmt sind.
Sind Sie bereit, vom architektonischen Verständnis zur praktischen Umsetzung überzugehen? Laden Sie „Process Digital Twins Simplified with Simio“ herunter, um Zugang zu detaillierten Implementierungsrahmenwerken, Fallstudien aus der Praxis und umsetzbaren Strategien für den Start Ihres ersten Pilotprojekts und die unternehmensweite Skalierung zu erhalten.