
Search the Community
Showing results for 'Failure'.
-
I extended the previous model a little bit because i want to measure how often the servers are idle. I implemented that the following way: As soon as one server is idle it fires an event and all the other servers are idle too. Is one server idle, all servers have to stop working. Because you can consider it as an assembly line. And i count how often the event is fired. All servers fire the same failure event. But i don't know how to repair the servers as soon as the idle server gets a new entity again. Because as soon as the idle server has new material the assembly line (all servers) can start working again. But i can't handle that with an add on process and an event because its only allowed to fire an repair event when it was idle before. So i don't know how to do that. I hope you can help me with that too. In the example i let the servers be repaired after 3 minutes. And do you know if i can get a graph at the end of the simulation which shows at which time for how long the servers had a failure or were idle? Because under results i only see how often and how long they were idle but not when. Is that possible to get that information? Thanks a lot for your support! HeuristicTest3.spfx
-
I want to monitor the total inventory of all servers. Lets say only InputBuffer of all Servers is enough. So i want to see how much buffer i need/have when i have random server failures, repair times and changing processing times (later i also want to add random arrival times). So therefore i was focusing on the HourlyStatistic Simbit which i think is really helpful to get started with the Plots. Because i have many servers i did like in Simbit recommended and created a Server Object. With the intention that i can monitor the inventory of all servers together without doing the assignments for every single server. And then i created some experiments with the total inventory as a response value. I add a small model where u can see my experiments. So it worked but i can only see the inventory for each server. But i want the combined inventory. Goal of my model: Analyzing / Monitoring actual inventory level of all servers while changing failure rates, repair time and processing time. Problems: --> How can i monitor the inventory of all servers together, in the experiments as well as in the plots? I thought i could do that with the server object. --> Can i change a standard library server to my created server object without deleting already created servers and entering everything again? Thank you very much again, that forum helped me already a lot.I hope i could describe my problem clearly. (The model i added consists of 2 servers, 2 sinks, 2 sources. The vehicle transports the entities to the servers. Servers have random failure, repair and processing time. Vehicle drives always the same fixed tour and delivers specific entity to specific server.) InventoryMonitoring.spfx
-
1) (MyServer1.InputBuffer.Contents+MyServer2.InputBuffer.Contents)--> this expression defines your total intventory level of "Your Servers" (subclassed ones). You can use this expression directly or can assign it to a state variable then use that one. You can type this expression into a response in your experiment. Meanwhile your model looks incomplete (seems lack of failure logic). 2)Absolutely sure you can, sublcass server object from std. lib. and add your old or new (in fact, both will be new to the sublcassed object but they do not mind). At the end you will have two subclassed server objects named MyServer and MyServer2 (see navigation window).
-
I have several servers which have failures at the same time. The failure is triggered through a randomly fired event. But i also want the servers to be repaired at the same time. So first my idea was to use an Input Parameter for the "Time to Repair" section for each Server.Because i want a random distributed repair time which changes every time the servers have a failure. But it should be for all servers the same repair time time. So for example failure 1, repair time: 4 min. Failure 2, repair time: 2 min. And that for all servers. I hope you know what i mean. How can i realize that?
-
Yes that was exactly what i wanted to do. Works perfect! But how i do that if i want to have several groups of servers with different failure and repairing times? So same situation but several groups with different behavior. Each group of server has its own failure and repairing times. Because i can't have several processes starting " OnRunInitialized". Otherwise i would just copy&paste the same for each group. To let them fail is not the problem. Therefore i can create an distributed timer for each group. For me the problem is again the repair time.
-
So if i understand correctly, you want all of the servers to fail at the same time, then get repaired at the same time? You could do it with a custom object, but perhaps there is a simpler way. 1) Create a Process that has 3 steps: -Delay until next Failure time. -Assign a custom state (for example TimeToRepairMyServers) a value drawn for a distribution. -Fire an event (like FailMyServers), then connect to input side of Delay to cause it to repeat the logic. 2) In each server's Reliability Logic: -FailureType: Event Count Based -Event Name: FailMyServers -Count Between Failures: 1 -Time To Repair: TimeToRepairMyServers All your servers will fail at the same time when the even is fired. And all will use the current value stored in TimeToRepairMyServers as their repair time.
-
I tried creating a process model to simulate a failure , for this what you realizadoes create a Timer event and a process that does is change the Current Capacity of the Path that connects my Sink with the rest of the model. The problem is I have a Node List where this point, while there is no event of failure in the Sink model runs smoothly , the Vehicle Trasnportes items from Source to the Sink, almomento a fault occur Path 's ability to change 0 as was to do processing, but equally my vehicle gets stuck on waiting Path to go to that Sink , rather than reevaluate and go elsewhere Sink. I tried changing the InputSink CurrentTravelCapacity and CurrentCapacity but equally I feel the same hopes to enter the Vehicle . How can I do to make the Vehicle reevaluate where to go to leave the body ? . the list of nodes containing 5 Sink logic Vehicle is go to the nearest Sink. Please show your support
-
I thought working with TIMER type RATE TABLE, in order to generate the probabilistic part, now how can I do for example if I have 5 SINK I can generate a process that simulate a playing capacity of PATH fails, but I do not want to happen to SINK all at once and if I create a process for each SINK the model would not be scalable because failure would have as many processes as SINK in my model.
-
The standard student version is limited to creating 5 object definitions. So I recommend using add-on processes to create custom object behavior. While it is possible to add a failure to any object, this requires some expertise to do so. Resources already have failures and states built-in. I would recommend seizing and releasing a resource using add-on processes and then applying the failures to that resource. Timer is just one way to create an event. Events can be triggered in many ways. For example, you could use the OnRunInitialized process in your model and have a series of Delay -> Fire steps (or more complex logic) to trigger a series of events.
-
I was already trying copying the SINK element but has failed me. create a property and a FAIL state to account for failure events but I can not see them from the model, my idea was to show a panel the number of failures. Additionally makes probabilistically make it fail. As data, try to copy editing a vehicle does not allow me to save object because it tells me I have too many objects. The ape license I have is student
-
I think you need to add 2 servers/ workstation one after source and one before sink. Here you can set failures. You can also copy a sink object and change it by adding Failure elements to it.
-
In real life it is a Failure, but I want to show that there is a difference at what time the failure occurs (7am-9am is worse than 9am-11am). So basically I need a scheduled Downtime. How do you make the first Delay? It seems that my "Failure" still starts at different times, even though the length of the Failure is correct. Is it possible to post another simple example like you did with the Combiner? That helped me a lot! Thank you for your support! Tom
-
"Must not work" - is this really a "failure" or just scheduled time when it cannot work. The latter is a bit easier. You just assign the capacity to 0 for a time period, then restore the capacity to 1. Use a Timer to create an event at time 7 hours, then every 24 hours. That event can trigger a process that delays for a random time of 0-2 hours, assigns capacity to 0, delays for another random time of about 10 minutes, then sets capacity back to 1.
-
Please elaborate on what you want to do. Are you looking for deterministic failures on demand? If so: -- One approach is to do this totally within processes using the Fail and Repair Steps. -- Another approach is to specify an Event-based failure on Server, then use process logic or even entity arrivals to trigger those events (and the resulting failures) on demand.
-
Hmmm, I have read through the Simbits. But couldnt find the solution to my problem. What do you mean by "the monitor element"? Or what does it do and where can I find it? If I want to stop the server for a couple of minutes every day during the same time of the day, do I even have to use the Failure Type or do I have to do it with Add on process triggers and some work arounds? Maybe Off-Shift? Thanks again, Thomas
-
Check the simbits and use the failure block with a element called monitor....
-
Hi all, I need help and guidance. I started with this dust suppression model and the file that I attached is what I came up with. I am going to make the dusty paths a sub-model but first I want to figure out all of the logic on a smaller scale. Now currently I have three paths that get watered. The water capacity/need of the path is represented by the three tanks and sinks next to them. Tank 1 is the filling station and it can be assumed that there will always be water. So the three paths represented three different levels of traffic. A higher traffic path has a faster flow rate towards the sink therefore it will need more frequent watering. What I need now is to define lets say 14 water trucks that I can separately monitor, that wont get destroyed at the end of their run and that park at a parking station until they are needed again. I also want to attach a certain failure logic to each of the trucks. I have tried using vehicles but I'm struggling to get the process logic working. I'm am still quite new to simio so I might be missing things. I'll appreciate any inputs. Thank you very mutch Carl-Gustaf Dust.spfx
-
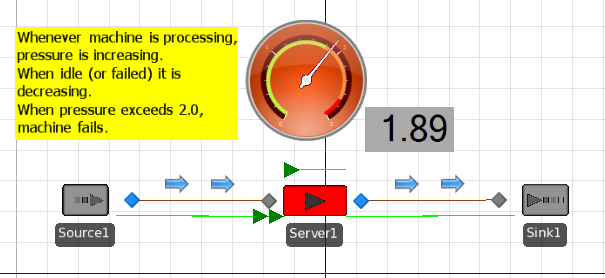
Thanks Dave for your example, however, we want to trigger the maintenance based on the failure probability of the machine not based on the pressure value. the failure probability if a function of (x,Y). let say that: Pressure = X(t)= kt, t= processing time, k=constant Temp= Y(t)= sin(t)+6t Failure Pr.= P(X,Y) Po= 0.75. >> threshold if Pr(X,Y)=> 0.75 stop the machine. my first thought was to model those two measures as resources put then I couldn't figure out a way to link that with the reliability logic
-
I'm trying to model a machine with two sensors, one measures pressure and the other measures vibration. the machine failure rate depends on those values that we need to monitor. lets say that both measures are function of time. X(t)= Pressure Y(t)= Temp. the failure rate will be a function of x and y and we want to trigger the maintenance if the conditional failure probability exceeds the threshold. any idea or hints on how to model this in simio? ~Ali
-
1) Start by representing your Pressure and Temp as States of type Level (see Definitions > States). These state values can continuously change based on the value of a rate. Setting that rate to +, - or 0 is something you can do wherever appropriate in your model. (Example: have a state named Pressure, and assign Pressure.Rate to its rate of change based on what causes it to rise or fall). 2) Create a Monitor for each State (Definitions > Elements) of Type CrossingStateChange with an appropriate Initial Threshold Value. When the value of the state being monitored crosses the threshol value, it automatically triggers an event named MonitorName.Event. (Example: have a Monitor named PressureExceeded and set its threshold at a maximum pressure allowed (e.g. 250)) 3) If you just had a single monitor, then on a Server you could specify reliability logic with a failure of type Event Count Based and use the event from that monitor (Example: Fail each time PressureExceeded.Event occurs). You don't say if you intend to use a Server or a custom machine. The basic approach above will work in either case. But to deal with multiple sensors might require some custom processes or a custom object because the Server is designed to deal with only one failure stream. There are several ways of approaching multiple failure streams depending on your objectives. Here is a simple model in 5.81 to illustrate:ServerFailsBasedOnSensor.spfx
-
I am trying to model a server with several failures, where each failure may have a different explanation and thus, a different pattern. One obvious approach is subclassing a Server and defining additional elements, such as Failure, Timers, etc and modify the processes so that several failures can cause the downtime of the server. However, I do not feel very comfortable with the scalabitliy of this approach. I mean, if a server has three types of failures I will have to add two new Failure elements, 8 timers, 4 corresponding to each Failure and so on. If at some point in time I need to add an additional failure, I would need to do the adding all over again, an so on. I am considering two different approaches for this, but I do not know if these are feasible or if there is a far better approach. Approach 1. I would like to subclass the server and create a Repeat Group property so that the user, by means of adding rows, may characterize as many failures as desired. The thing is, is is possible to modify the processes so that they are general enough to reflect any number of failures (with their corresponding characterization)? Approach 2. I was thinking of creating a new object, let us call it objFailure, which contains definitions and processes to reproduce the behaviour of a failure type. The idea would be that this objFailure has a property which would contain the number of an element within the project, so that when objFailure fails, the corresponding object fails. This way, modelling a server with several types of failures woukd consist in creating that server and as many objFailure as required, which would cause the server to fail as they themselves fail. The issue with this approach is that it may not be that easy to represent interferences among failures. For example, if objFailure1 is a count based event failure and objFailure is a Processing Time based failure, when objFailure1 occurs, the server stops and the time during which is down should not be taken into account by objFailure2. This may very complex to program effectively and efficiently.
-
I would abandon using Simio's built-in elements and do this all in a process with repeat groups plus delay steps and custom token states as you describe in Option 1. You could use the search step to spawn a new token for each row in the repeat group which would provide scalability, which then gets a delay time randomized according to an input distribution for that row of the repeat group. At the end of the delay time it would trigger a failure. These tokens effectively become your timers instead of using timer elements. The failure could suspend this 'timer' process such that the other delays stop counting during a timer. This token would then loop back on itself, having a different delay again. However, my conclusion (but not implemented yet) was that I would use the 'non-scalable' approach. The reason for this is that adding more than 2-3 failure distributions is getting overly complex/detailed and isn't likely to add value and could even possibly subtract from it! Not only that but I've found that when I combine different types of events (in reality, not modelled) they almost always result in some fairly good erlang/exponential/log-normal distributions. These only need to be split out to remove multiple peaks rather than getting to the exact causes. Not only that, but I've often found that failure data (not models) is recorded very poorly, and often mis-reported. For example a 'slow operation' is instead recorded as a failure. Alternatively, short failures are not recorded at all because the operators are busy fixing the problem. Because of this going into the level of detail you've described is going beyond the quality of the data. If you actualy trust your failure data, by all means go to town with the scalable approach. If you were part of my firm, I would give you feedback along the lines of "never trust failure data" However, a colleague of mine does feel differently so this is not a hard and fast rule -- just my experience.
-
Simple approach: Take advantage of the fact that each model has an OnRunInitialized process that is called at the start of each run. --Create a table that contains all your initialization data. This might optionally be bound to an external file and automatically read if it changes frequently. --Define the OnRunInitialized process to search that table, create the entity(s), initialize the entity, and transfer it to the correct location. Look at the Simio Example (not SimBit) named RPsixample for an example of this approach applied to a simple scheduling model. More comprehensive approach: Take advantage of the fact that each object has an On Initialized add-in process that is called at the start of each run. --Create a table that contains all your initialization data identified by object instance. This might optionally be bound to an external file and automatically read if it changes frequently. --Define the On Initialized process to search that table for a matching object instance, create the entity(s), initialize the entity, and transfer it to the correct location. This can also set object characteristics as well, such as status, capacity, failure data, learning curve, … While this could be used by simply specifying the add-on process in each object instance, it is even more powerful if you create a custom object that includes a custom object-specific initialization process.
-
I've copied the vehicle from the standard library vehicle and revised it to include: Travel time based failures, calculated from the resource state Transporting. This failure time does not include OffShiftTransporting or FailedTransporting. These failures will occur mid-link. Distance travelled failures, recorded from the link length when the transporter arrives at the end of the link. These failures can only occur at the end of a link. Created in Sprint 4.72. VehicleWithTravelTimeBasedFailures.zip VehicleWithTravelTimeBasedFailures.zip
-
You can use Simio at several levels. Here are a few: • You can build simple models entirely within a Process (limited or no use of library objects). • You can use the Standard Library. This was designed to make it easy to do the more common applications, but is not intended to do everything. This library will be enhanced and supplemented with other libraries in the future. • You can enhance the Standard Library Objects via add-on processes. This functionality is still under development, but processes will be easy to define to supplement the OnEntry and OnExit behavior. For example, you may want to collect and report custom statistics or have custom exit logic. • You can enhance/replace the Standard Library Objects by inheriting from them and modifying any of the predefined behavior. For example the Server currently only allows a single failure stream. You could create a new MyServer object that reproduces the included logic to support three failure streams. • You can create entirely new objects by inheriting from base class objects (like Fixed Object, Link, Node, and Intelligent Object). With this approach you can graphically define any combination of properties and behavior that you want using Steps and Elements inside Processes.










